
深度学习从入门到实战:从感知机、反向传播到训练工程
这是一条从“单个神经元如何分类”出发,逐步走向 多层网络、自动微分、优化器、学习率调度、归一化与正则化 的完整学习路径。
阅读导航
- 模型起点:感知机如何学习线性决策边界?为什么 XOR 迫使网络走向多层?
- 训练核心:前向传播、损失函数、反向传播与优化器如何组成闭环?
- 代码实战:如何从零实现 MNIST MLP,并理解 PyTorch 自动微分?
- 训练工程:如何选择调度器、初始化、归一化与正则化策略?
⭐ 核心结论 / 面试高频
深度学习训练的统一闭环是:前向传播得到预测 → 损失函数量化误差 → 反向传播计算梯度 → 优化器更新参数 → 验证集评估泛化能力。
1. 从感知机到多层感知机
1.1 感知机的发展
⭐ 核心结论:感知机
感知机接收一组输入特征,通过错误反馈学习权重与偏置,最终寻找一个能够区分类别的线性决策边界。
它是人类历史上第一个真正落地的可学习机器方案,让机器不再依赖人工编写的规则,而是自动从数据中学会分类。
虽然诞生于1957年,但它麻雀虽小,五脏俱全。完整包含了神经网络所有核心要素的雏形:输入、权重、求和、激活、误差反馈、参数更新。真正理解了感知机,就相当于掌握了神经网络的完整骨架。
💡 历史脉络:M-P 神经元(1943)
麦卡洛克与皮茨 联合发表了论文。
- 将生物神经元抽象为一个简单的逻辑单元。
- 同时接收多个兴奋或抑制信号。
- 当兴奋信号的总量超过某个阈值时,神经元激活并输出信号,否则保持沉默。
缺陷:权重必须由人工设定,机器本身无法学习。它只是一个精巧的逻辑装置。
💡 历史脉络:赫布理论(1949)
转机出现在1949年,心理学家 唐纳德·赫布出版了《行为的组织》。
- 如果两个神经元经常同时激活,它们之间的连接就会不断增强。
- 反之,如果不常同时激活,连接则会逐渐减弱。
- 这是人类历史上第一次从学习机制的角度解释神经连接的变化。
- 第一次给出了一个关键问题的生物学依据————权重是可以改变的。
💡 历史脉络:第一台会学习的机器(1957)
弗兰克·罗森布拉特 在M-P神经元的基础上,加入了至关重要的创新:让权重通过错误反馈自动调整。
- 机器每做出一次错误预测,权重就自动修正一次。
- 如此反复,直到学会正确分类。
- 1958年,他亲手造出了一台真实的物理机器———— Mark I Perceptron。
让机器学会分类
感知机的工作原理非常简单:对输入做加权求和,与阈值比较做出判断,根据错误反馈微调修正权重,直到学会正确分类。
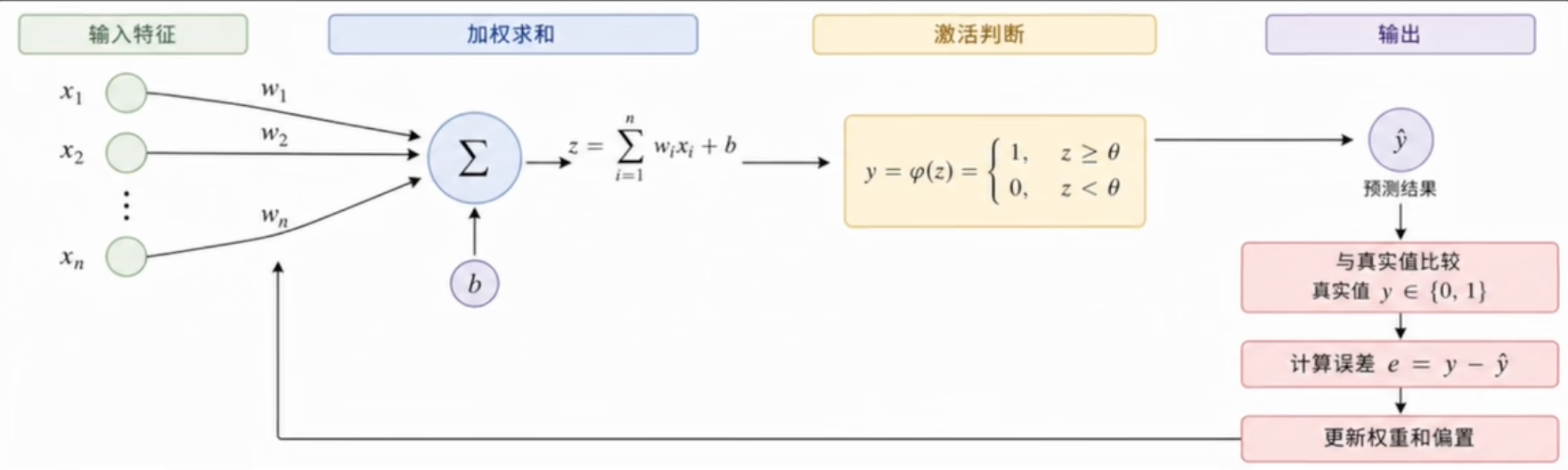
⚡ 易混淆点:感知机不等于逻辑回归
把阶跃函数替换为 Sigmoid 只能得到相似的模型形式。逻辑回归通常通过最大似然 / 交叉熵训练,而感知机使用误分类驱动的更新规则;二者的目标函数、概率解释和优化过程不同。
1.2 感知机的计算与学习规则
感知机执行步骤
⭐ 第一步:输入与加权
接收一组输入信号
每一个输入对应权重
- 在特征尺度一致且其他变量固定时,
越大,输入 对线性打分的局部影响通常越明显。 - 权重接近
,表示该特征对当前线性打分贡献较小。 - 不能脱离特征尺度、相关性与数据分布,直接用权重绝对值断言全局重要性。
⭐ 第二步:求和与判断
把输入加权求和,得到预激活值
其中
⭐ 第三步:错误与修正
每做出一次预测,感知机就把结果和正确答案对比。如果预测正确,什么都不用做;如果预测错误,就按照下面的规则调整权重:
是真实标签, 是感知机预测,两者之差是误差信号。 是特征的输入值,误差要按照输入的大小来分配责任。 是学习率,控制每次调整的幅度。

案例:预测身材偏胖还是偏瘦
为了让感知机的工作过程更直观,我们来做一个具体的案例:判断一个人的身材是偏胖还是偏瘦。
- 输入特征:收集一批人的数据,提取两个特征:
(身高)和 (体重)。 - 数据处理:消除身高和体重的量级差异,将数据压缩到0~1之间(归一化),保证学习稳定。
- 目标标签:偏瘦标记为0,偏胖标记为1。
- 训练过程:让感知机从对特征一无所知(权重为0)开始,不断看数据、预测、对比、修正权重。
⭐ 收敛条件
当训练数据线性可分时,感知机学习规则能在有限步内找到一个分离超平面;该边界通常不唯一,也不保证间隔最大。
| 序号 | 特征1 (身高) | 特征2 (体重) | 标签 (体型) |
|------|-------------|-------------|------------|
| 1 | 175 | 71 | 偏瘦 |
| 2 | 160 | 63 | 偏胖 |
| 3 | 172 | 69 | 偏瘦 |
| 4 | 162 | 65 | 偏胖 |
| 5 | 170 | 66 | 偏瘦 |
| 6 | 164 | 67 | 偏胖 |
| 7 | 168 | 64 | 偏瘦 |
| 8 | 166 | 69 | 偏胖 |
| 9 | 165 | 62 | 偏瘦 |
| 10 | 168 | 72 | 偏胖 |数据归一化
本例中身高范围为
归一化后的数据 (X):
------------------------------------------------------------
| 序号 | 特征1 (身高) | 特征2 (体重) |
|------|--------------|--------------|
| 1 | 1.0000 | 0.9000 |
| 2 | 0.0000 | 0.1000 |
| 3 | 0.8000 | 0.7000 |
| 4 | 0.1333 | 0.3000 |
| 5 | 0.6667 | 0.4000 |
| 6 | 0.2667 | 0.5000 |
| 7 | 0.5333 | 0.2000 |
| 8 | 0.4000 | 0.7000 |
| 9 | 0.3333 | 0.0000 |
| 10 | 0.5333 | 1.0000 |
验证归一化范围:
特征1范围: [0.0000, 1.0000]
特征2范围: [0.0000, 1.0000]
============================================================定义感知机类
__init__负责设定超参数,fit是训练的入口。权重初始化为0,意味着感知机一开始对两个特征一无所知。每轮遍历所有样本,犯错就更新权重,没错就跳过。当某一轮所有样本都预测正确时,训练结束。
🔍 展开查看:代码实现
class Perceptron:
def __init__(self, learning_rate=1.0, n_iterations=100):
self.lr = learning_rate # 学习率
self.n_iterations = n_iterations # 最大训练轮数
self.weights = None # 权重 w
self.bias = None # 偏置 b
self.errors_per_epoch = [] # 记录每轮错误数
def fit(self, X, y):
n_samples, n_features = X.shape
# 权重和偏置全部初始化为0
self.weights = np.zeros(n_features)
self.bias = 0
self.errors_per_epoch = []
for epoch in range(self.n_iterations):
errors = 0 # 本轮错误计数
for idx in range(n_samples):
x_i = X[idx]
y_true = y[idx]
# 1. 计算加权和: z = w1 * x1 + w2 * x2 + b
z = np.dot(self.weights, x_i) + self.bias
# 2. 激活判断: z >= 0 输出1,否则输出0
y_pred = 1 if z >= 0 else 0
# 3. 计算误差
error = y_true - y_pred
# 4. 如果预测错误,更新权重和偏置
if error != 0:
self.weights += self.lr * error * x_i # 更新权重
self.bias += self.lr * error # 更新偏置
errors += 1 # 错误计数
print(f"第{epoch+1}轮,第{idx+1}个样本,更新权重:{self.weights},更新偏置:{self.bias}")
self.errors_per_epoch.append(errors)
# 本轮零错误 -> 收敛,训练结束
if errors == 0:
print(f"第{epoch+1}轮,错误数归零,训练收敛!")
break
return self
def predict(self, X):
# 计算加权和:z = w1 * x1 + w2 * x2 + b
z = np.dot(X, self.weights) + self.bias # type: ignore
# 激活判断:z >= 0 输出1,否则输出0
return np.where(z >= 0, 1, 0)开始训练
创建感知机实例,学习率设为0.5,最大训练100轮。调用fit开始训练,控制台会打印每一轮的权重变化过程。
model = Perceptron(learning_rate=0.5, n_iterations=100)
model.fit(X, labels)验证所有样本
🔍 展开查看:代码实现
predictions = model.predict(X)
for i in range(len(X)):
true_label = "偏胖" if labels[i] == 1 else "偏瘦"
pred_label = "偏胖" if predictions[i] == 1 else "偏瘦"
status = "✅" if predictions[i] == labels[i] else "❌"
print(f"样本{i+1}: 真实={true_label}, 预测={pred_label} {status}")
print(f"\n最终参数:w1={model.weights[0]:.4f}, w2={model.weights[1]:.4f}, b={model.bias:.4f}") # type: ignore可视化决策边界与训练曲线
经过若干轮训练之后,感知机最终会收敛到一组合适的参数,能够正确区分所有样本。这条在二维平面上把“偏瘦”和“偏胖”分开的线,就是感知机找到的决策边界。
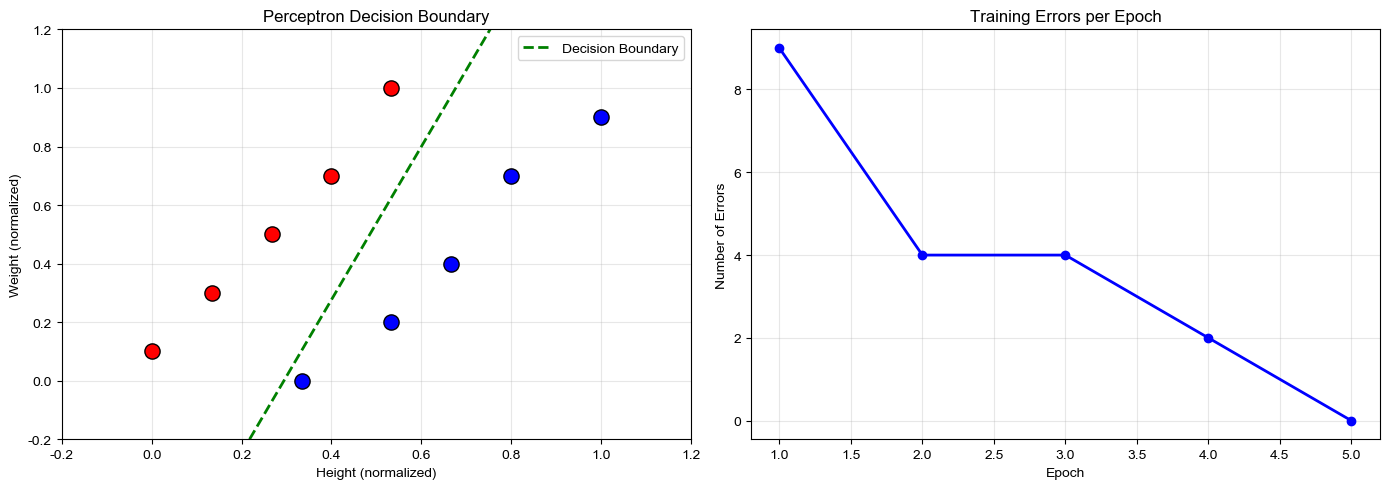
左图展示感知机在二维平面上找到的那条“决策边界”————把偏胖和偏瘦分开的直线。
右图展示每轮训练的错误数变化,可以直观看到模型的学习过程:从一开始错误不断,到最终错误归零。
用训练好的模型预测新样本
训练和推理必须使用同一组归一化统计量。下面部分新样本超出了训练集最小值或最大值,因此变换结果可能落在
身高=168cm, 体重=48kg -> 偏瘦
身高=162cm, 体重=82kg -> 偏胖
身高=175cm, 体重=70kg -> 偏瘦1.3 单层感知机的边界:线性不可分
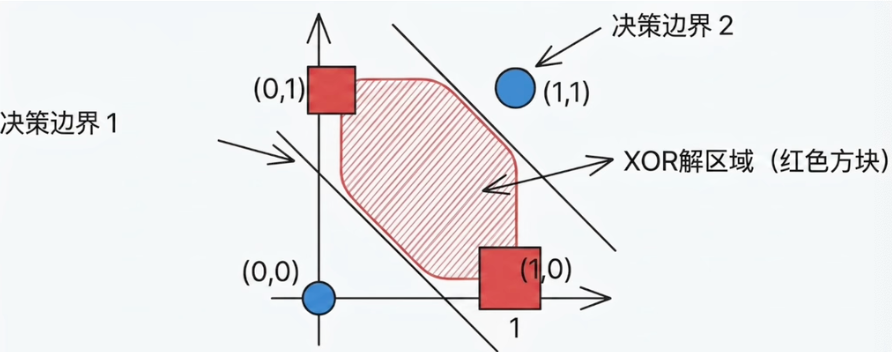
感知机只能解决线性可分的问题。但现实中的数据往往没有这么听话。逻辑运算中的XOR(异或)问题将这个缺陷暴露得淋漓尽致:
- XOR规则:输入相同时输出0,不同时输出1。
- 不存在一条直线能将其完整地分开。
- 这不是技巧问题,而是数学上的根本限制————XOR是线性不可分的
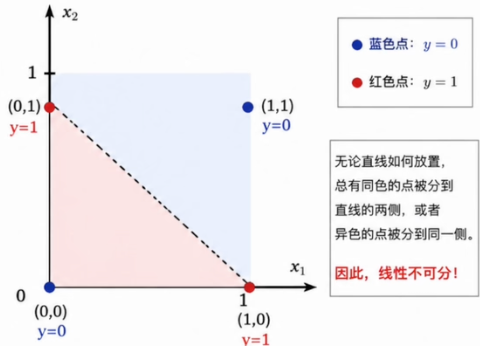
⚡ 感知机收敛定理的适用边界
只有线性可分数据才保证有限步收敛。遇到 XOR、标签噪声或类别重叠时,错误数可能长期不归零,应设置最大轮数并在独立数据上评估泛化能力。
1.4 多层感知机:用组合突破线性限制
复杂功能可以由简单模块组合
XOR问题在逻辑电路中早已解决,计算机的异或门是由更基础的门电路组合而成的。
:至少一个输入为1。 :两个输入不能同时为1
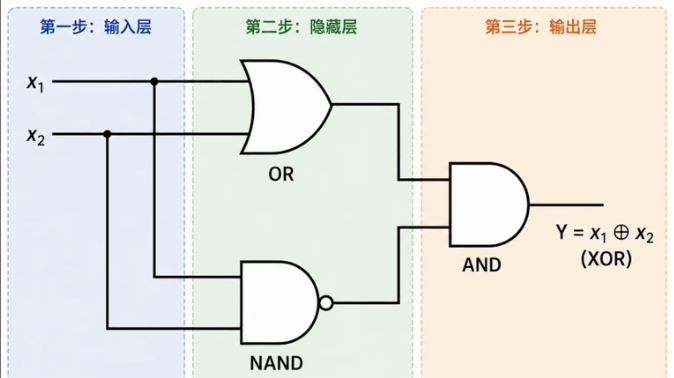
- 核心思想:复杂功能可以由简单模块层层组合得到。
多条线围出复杂区域
把基础功能的感知机组合堆叠,就可以解决异或这样的复杂问题。
- 单个感知机在特征空间里画一条线,只能做线性分割。
- 如果有两个感知机,就有两条线;三个感知机就有三条线。
- 有限条线可以组合成多边形分区;增加神经元与层数后,可以表达或逼近更复杂的非线性边界。
用两层感知机解决XOR
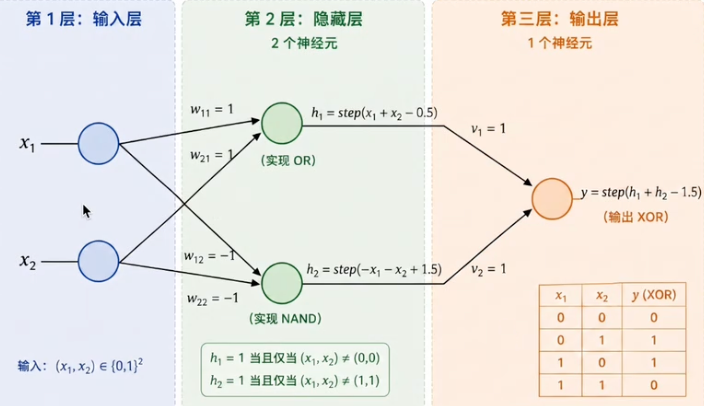
- 输入层:接收两个特征
、 - 隐藏层:两个神经元使用不同的权重做并行运算,各自画一条分割线,输出0或1
- 输出层:将隐藏层的两个输出作为输入,再做一次加权求和与激活,得到异或判断
第一个隐藏神经元学会了至少一个输入为1,第二个学会了不能同时为1,输出层把两个条件取交集。
1.5 MLP 的一般结构与非线性
多层感知机按层排列、层间全连接,构成了多层感知机(MLP)。
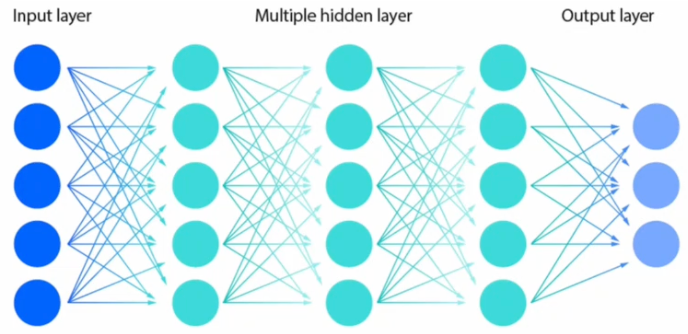
- 输入层接收原始特征,数个隐藏层进行中间运算,输出层给出最终结果。
- 同一层里的神经元并行提取多个不同的特征或规则。
- 后续层将前一层的输出作为输入,利用不同的权重进一步组合,逐层构造出更抽象、更有用的表示。
数学表达:函数的层层嵌套
线性难题:
如果每一层只是线性变换,那么无论堆多少层都是徒劳的。
假设第一层输出为
令
💡线性变换的组合仍是线性变换。层层叠加,做的全是无用功。
解决方案是在每个神经元的加权求和输出上,套一个非线性函数,称为激活函数(Activation Function):
有了非线性的
1.6 表达能力不等于可训练性
多层感知机的理论能力:
⭐ 万能逼近定理的正确理解
在满足特定激活函数、紧致定义域等条件时,具有足够宽度的单隐藏层网络可以任意逼近连续函数。
- 它说明的是存在性与表达能力,不保证有限宽度下容易训练。
- 它不保证梯度下降能找到该参数,也不保证样本有限时能够泛化。
- 深度网络的价值不仅是“能表示”,还在于某些函数可以被更高效地表示和学习。
如何训练模型仍旧是个问题
- MLP结构在1960年代就已经被提出。问题不是没人想到多层,而是没法训练。
- 当时的感知机学习规则只适用于单层网络。
- 核心难题:隐藏层的误差该怎么分配?输出层的错误我们看得到,但中间那些隐藏神经元,每个该为最终错误承担多少责任?没人知道怎么算这个梯度。
💡直到1986年,反向传播算法(Backpropagation)与多层网络结合,提供了一套高效计算多层梯度的方法。
2. 神经网络如何完成一次训练
2.1 训练闭环总览
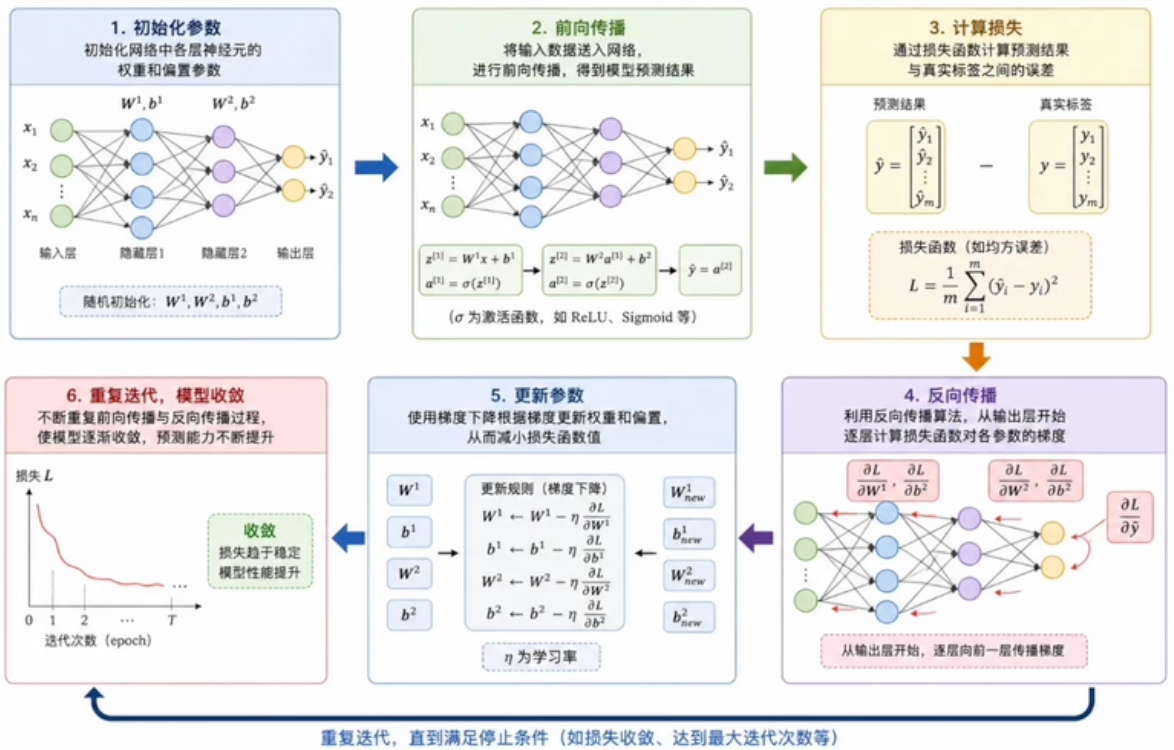
- 初始化各层神经元的权重和偏置参数;
- 输入数据做前向传播,得到预测结果;
- 用损失函数计算预测与真实标签的误差;
- 用反向传播从输出层逐层计算损失对参数的梯度;
- 用梯度下降根据梯度更新权重和偏置;
- 不断重复,让模型逐步收敛。
2.2 前向传播:从输入到预测
数据沿网络从输入流向输出:线性加权 -> 加偏置 -> 激活函数,把信息重构为更高阶特征传递给下一层。
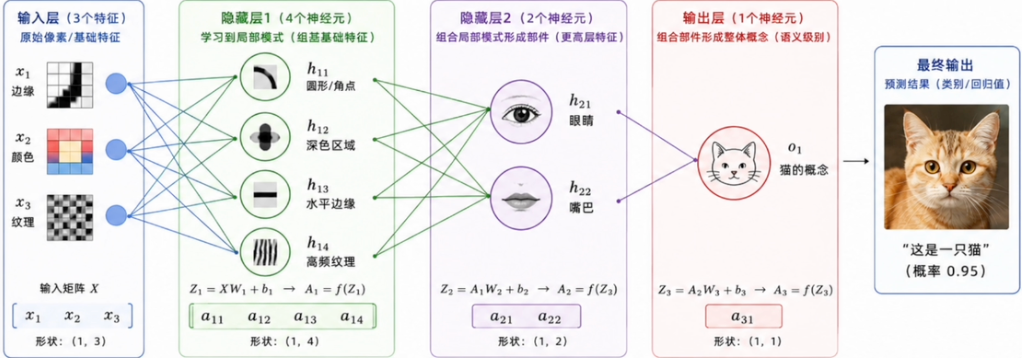
- 正是这种逐层抽象的机制,让神经网络具备了自动学习特征的能力。
2.2.1 单个神经元与整层矩阵化
每个神经元都做同一套两步操作
- 线性变换
- 非线性激活
差别只在于:每个神经元维护着自己的一套权重和偏置。以下图为例,仅参考(3输入 -> 4神经元):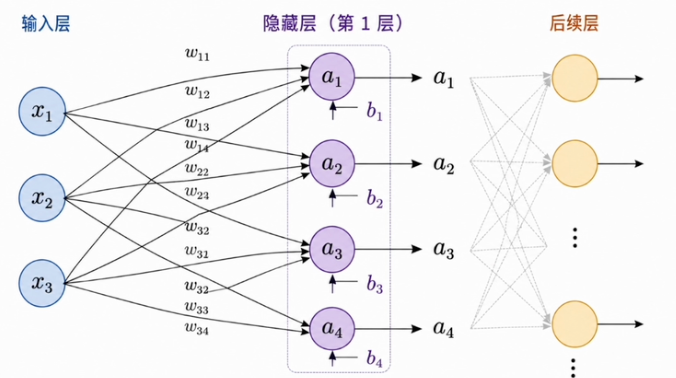
从单神经元到整层矩阵化
第
为了运算效率,把同一层所有神经元打包成矩阵,一次乘法搞定整层:
示例:
同时解释了为什么神经网络计算天然适合GPU —— 它就是一连串大型矩阵乘法。
2.2.2 激活函数:为网络注入非线性
前言
- 为什么需要激活函数?
🔍 展开查看:没有激活函数时为何仍是线性模型
假设去掉所有激活函数,一个三层神经网络的输出:
把括号展开后整体退化为一次线性变换:
💡无论堆多少层,没有激活函数的神经网络始终是一个线性模型。
激活函数的作用:在每一层插入一道非线性的“弯”,让神经网络得以拟合任意复杂的函数。
- 为什么不把
改成非线性?
🔍 展开查看:为什么保留“线性变换 + 非线性激活”
- 线性运算的工程红利
- 硬件加速:GPU/TPU就是为矩阵乘法量身打造的,cuBLAS几毫秒就能算完亿级规模的
。 - 梯度极简:
,反向传播一行公式搞定。
一旦把它换成复杂非线性,这些红利全部消失。
- 数值指数级膨胀
以
- 前向:数值冲向无穷大或归零,模型瘫痪。
- 反向:求导系数巨大,梯度彻底失控。
激活函数需求:
- 非线性:最基本门槛,否则深度毫无意义。
- 几乎处处可导:反向传播必须乘上它的导数。
- 梯度行为良好:不消失也不爆炸,最好接近1。
- 计算便宜:训练中会被调用上亿次。
- 输出零中心:避免梯度方向被绑死,优化更顺。
- 单调/平滑/有界
- 一个好激活函数,是在表达能力、梯度传播、计算成本和数值稳定性之间取得平衡。
阶跃函数
阶跃函数(1958):最朴素的激活
1958年,罗森布拉特用阶跃函数搭出了感知机。
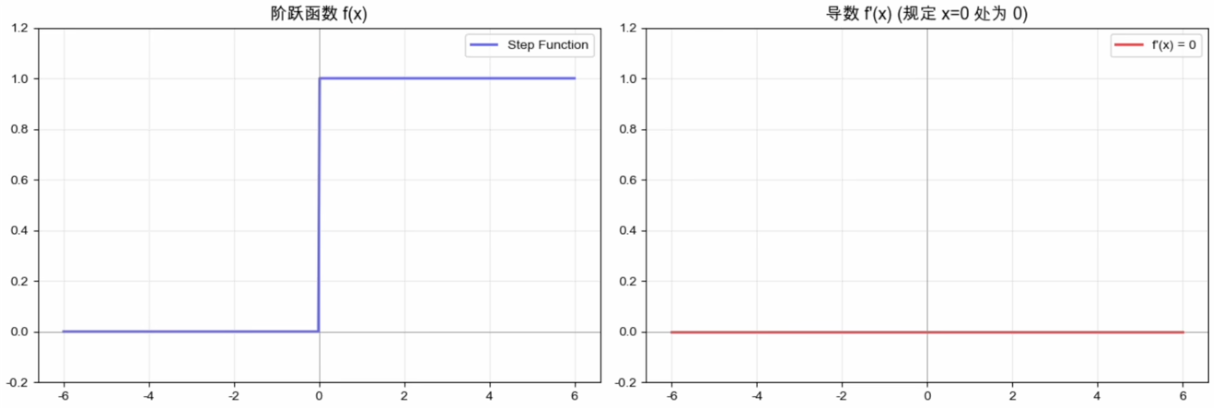
- 梯度无法有效传播:除
外导数为 ,而 处不可导。采用常规反向传播时,误差信号会被清零,无法用梯度法训练多层网络。 - 信息损失太狠:输入是0.001还是1000,输出都是1。网络丧失对“程度”的感知,大量数值信息在激活的瞬间被永久丢弃。
Sigmoid
Sigmoid(1986):把开关变成旋钮
1986年辛顿等人把反向传播带回神经网络,它需要一个处处可导的激活函数————他们沿用了19世纪就用来描述人口增长的函数:
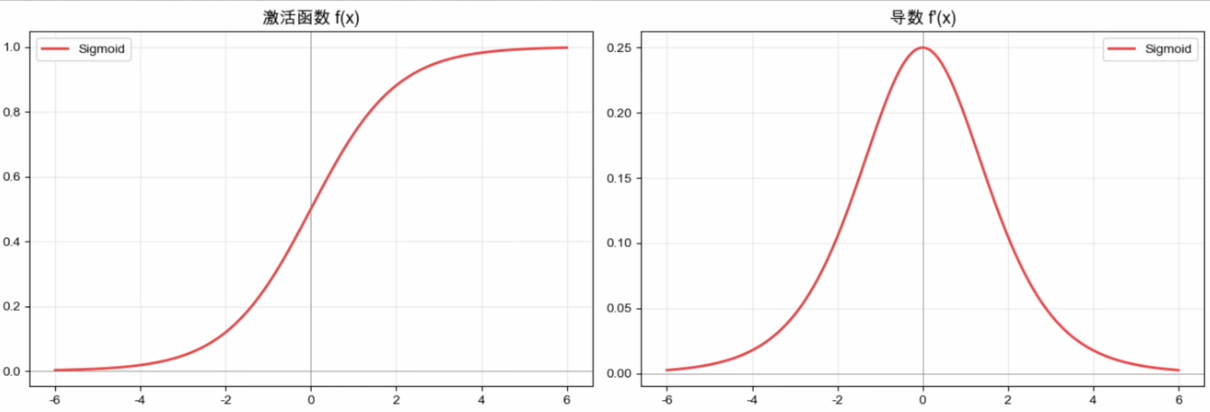
一条平滑的 S 形曲线,输出严格位于
优势:
- 几乎处处可导且平滑:相较阶跃函数,可在常规输入上提供连续梯度信号。反向传播并不要求激活函数严格处处可导,ReLU 在
处不可导也能通过次梯度约定训练。 - 概率建模接口:输出位于
, 时取 ;与伯努利似然 / BCE 配合时适合二分类或多标签输出。概率是否校准还需单独评估。 - 平滑过渡:输入1.5和1.6输出有微小但有意义的差异,神经元终于有了“模拟感”。
劣势:
- 梯度消失:导数最大值只有0.25,但反向传播每过一层梯度就要乘一次导数,深层梯度越来越小,几乎学不动。
- 输出非零中心:输出永远是正数。下一层在反向传播时算出来的梯度往往同号。权重更新失去灵活性————优化器走Z字折线,无法直奔最优。
- 计算贵 + 天然饱和:含指数项,比简单乘法贵得多;指数式压缩使两端斜率以指数速度衰减。
💡如今Sigmoid主要保留下来的位置,是二分类任务的输出层。
Tanh
Tanh(1990s):把Sigmoid摆正
90年代初,杨立昆在贝尔实验室研究手写数字识别,被Sigmoid的非零中心训练震荡困扰。1998年的Efficient BackProp中他系统总结了Tanh的优势:
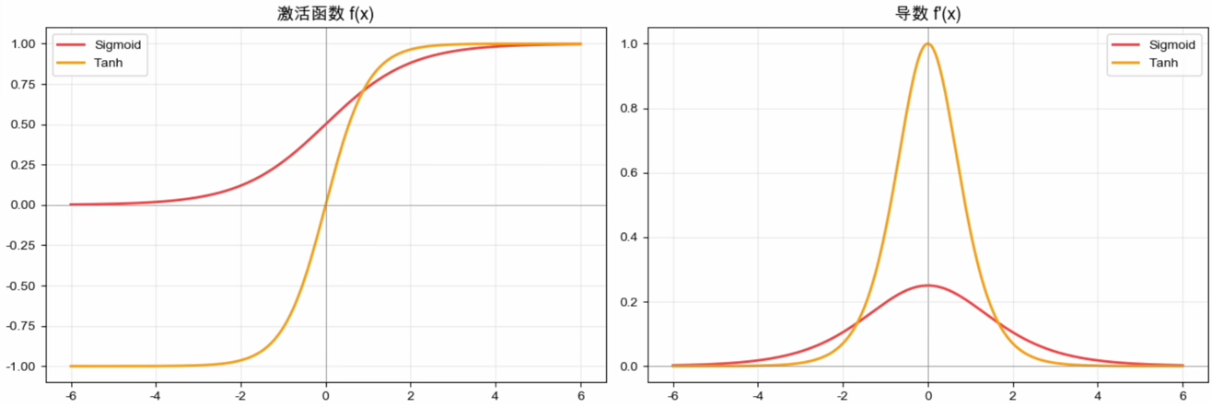
输出范围被拉伸到(-1, 1),关于原点对称。
✅改进:
- 导数最大值1,比Sigmoid大4倍,梯度衰减更慢。
- 零中心输出,Z字震荡明显减轻,收敛更快。
❌仍然存在:
- 本质仍是S形————两端饱和没有变。
- 依赖指数函数,计算成本同样不低。
Tanh 曾广泛用于早期神经网络与循环神经网络。它改善了输出零中心问题,但没有从根本上消除深层网络中的饱和与梯度衰减。
ReLU
ReLU(2010):懒得动脑的天才
ReLU 的思想出现很早,并在 2011~2012 年前后的深度卷积网络中被广泛验证和普及。它的形式非常简单:
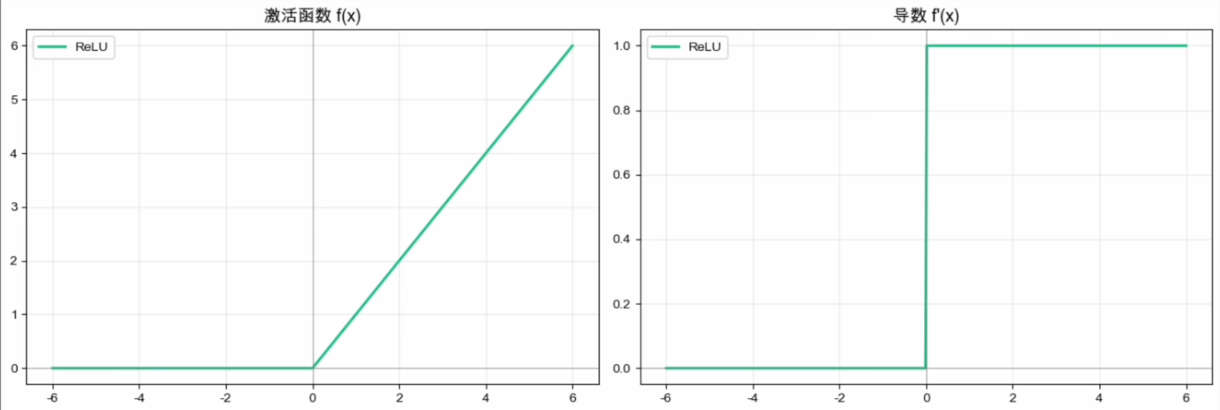
优势:
- 大幅缓解梯度消失:正半轴导数恒为1,链式法则在这里几乎变成“梯度直通车”,深层网络第一次真正能训。
- 计算极快:只需一次比较操作。没有指数、没有除法————大规模训练里被放大成可观的速度优势。
- 稀疏激活:负输入被置为
,部分神经元在一次前向中不激活;这可能带来计算与表示上的稀疏性,但不能等同于可靠的正则化。
代价:
- 死亡ReLU:某次更新后预激活值恒为负,则输出永远0,导数永远0————神经元彻底死掉,救不回来。
- 非零中心:输出要么0、要么正数。但在正半轴梯度直通车面前,这点Z字震荡基本可以接受。
- 输出无上界:深层网络中激活可能放大,需要合理初始化、残差连接、归一化或梯度裁剪等机制;ReLU 并不必然要求 BatchNorm。
ReLU 随现代卷积网络迅速普及,成为深度学习中最具代表性的隐藏层激活函数之一。
在2012年的ImageNet竞赛上,AlexNet把图像分类错误率一举降到15.3%————这样的优势在ImageNet历史上前所未有,所用激活函数正是ReLU。
AlexNet 的成功来自 GPU 训练、ReLU、数据增强、Dropout 与大规模数据等多项因素共同作用,不能归因于单一组件。
Leaky ReLU
Leaky ReLU:给负半轴留一条缝
既然ReLU在负半轴归零很“死”,那就给它留一个极小的斜率:
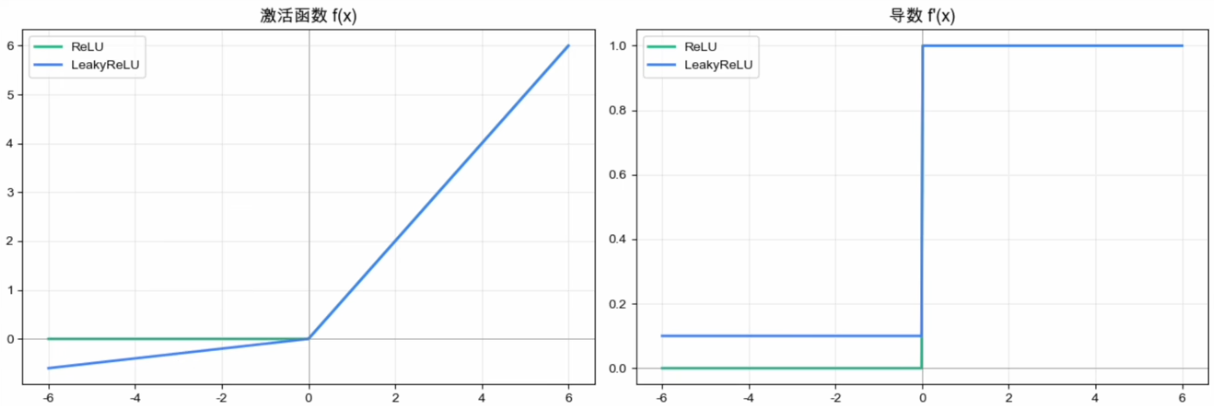
- 负半轴导数永远不为0,神经元不会彻底死亡。
- 当训练过程中出现大量神经元死亡时,可以一试。
- 但
是手动超参,0.01不一定最优;多数情况下ReLU + 良好初始化 + BatchNorm 已经够用。
GELU
GELU(2016):把硬门换成软门
ReLU在
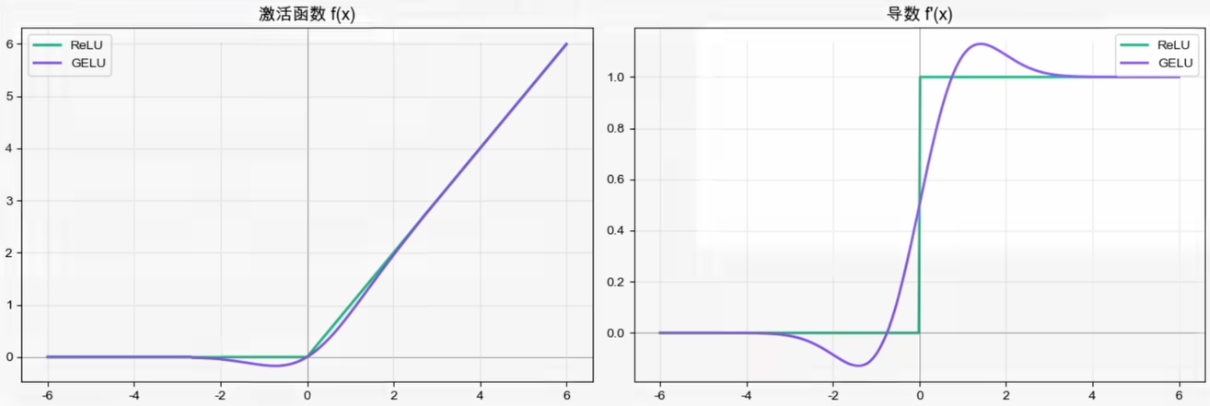
GELU 于 2016 年提出,并随 BERT、GPT-2、ViT 等架构得到广泛应用。不同 Transformer 家族并不统一:部分模型使用 GELU,另一些使用 SiLU/SwiGLU 等门控变体。
✅适用场景:Transformer类模型(BERT/GPT/ViT)的前馈网络层。
❌代价:需要tanh、三次方、平方根————比ReLU慢得多。
Swish / SiLU
Swish/SiLU:机器自己挑出来的
2017 年 Google Brain 在自动搜索激活函数的工作中推广了 Swish,其常用形式为:
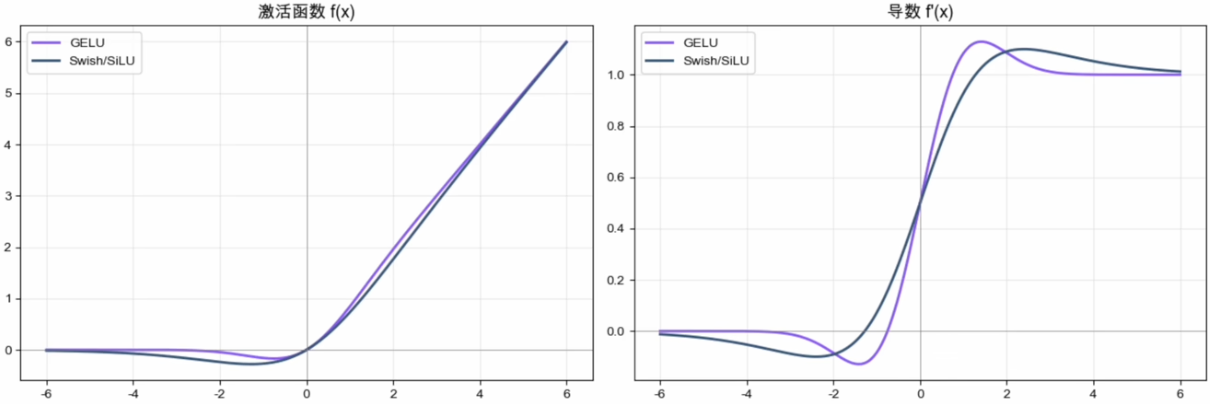
其实2016年Elfwing等人就独立提出过完全相同的函数————叫SiLU(Sigmoid Linear Unit)。PyTorch中即nn.SiLU。
相比GELU的优势:只需一个Sigmoid,计算更轻。
SiLU / Swish 的典型场景:
- 现代 CNN:EfficientNet 使用 Swish/SiLU;MobileNetV3 使用与之相关的硬件友好近似 H-Swish。
- 大模型FFN:LLaMA引领Mistral/Qwen/PaLM等开源大模型FFN采用SwiGLU。
- “想比ReLU多走一步”:在对计算稍敏感、又希望比ReLU更进一步的场景,Swish是高质量替代。
SiLU 与 GELU 的曲线形态相近但并不相同。现代模型还常使用基于 SiLU 的 SwiGLU 门控前馈层。
激活函数选型总结
激活函数80年演化
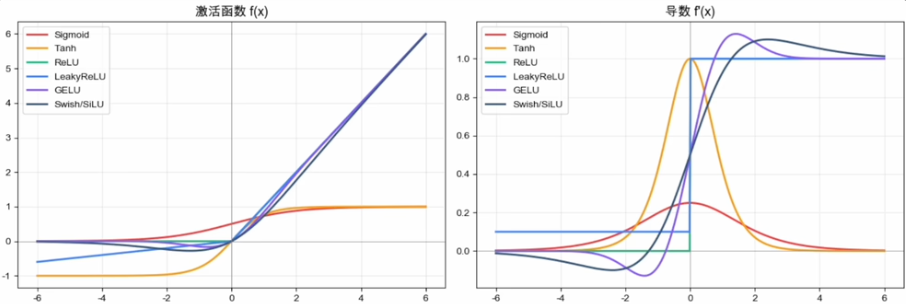
💡演化方向不是越来越复杂,而是越来越懂得在表达能力、梯度传播和工程效率之间做权衡。
- 典型位置:MLP、CNN 隐藏层。
- 优势:计算便宜,正半轴梯度稳定。
- 风险:ReLU 可能出现死亡神经元;Leaky ReLU 用负半轴小斜率缓解。
💡激活函数提供“非线性”,梯度下降提供“学习能力”————一个让网络能拟合任意函数,一个让网络能找到正确参数。
2.2.3 损失函数:把任务转成可优化目标
💡损失函数的作用:用一个数字告诉模型“你错得有多离谱”————再用这个数字的梯度告诉模型“往哪个方向改才能错得更少”。
这个“数字”就是损失函数的输出。它在训练里扮演三种角色:
- 度量:把预测
和真值 的差距量化成一个标量 。如果没有标量,就不能“哪个模型更好”了。 - 梯度信号源:反向传播从
起步。损失选的不一样,反向传播的起点信号就完全不同。 - 任务目标:“我要做分类”模型听不懂;“我要最小化交叉熵”模型才能执行————损失是把人类意图翻译给优化器的唯一通道。
MSE:回归任务
💡MSE是回归任务的默认损失
均方误差(Mean Squared Error),也叫L2 Loss:
优点:
- 消除符号抵消:先对误差平方,再求和或平均。
- 放大大误差:误差3平方变成9,误差0.4平方变成0.16,差异被显著拉开,让模型对大误差更敏感。
- 梯度随残差线性变化:离真值越远,梯度绝对值越大;接近真值时梯度变小。它不是 AdaGrad/Adam 意义上的“自适应学习率”。
局限:
- 对离群点过分敏感:平方放大是双刃剑。一个标签出错的样本(真值100,错标10000)贡献是
,会把整个batch的梯度都带偏。标签噪声大时切到Huber Loss(小误差MSE,大误差MAE)更稳。 - 假设目标连续可比:MSE默认“差2比差1严重4倍”。对房价、温度成立,对类别标签完全不成立————把猫预测成狗和把猫预测成飞机,从分类正误看是一样错的。
- 配合Sigmoid会梯度消失:这是MSE几乎不能用在分类任务上的根本原因。
🔍 展开查看:MSE 与 Sigmoid 的梯度饱和推导
设
正样本
按理说应该强烈更新,但 Sigmoid 在饱和区已经“压平”,
交叉熵:分类任务
⭐ 分类损失应具有的性质
- 概率语义与实现输入要区分
- 交叉熵的数学定义作用于概率分布;工程 API 通常直接接收 logits,内部完成数值稳定的 Sigmoid/Log-Softmax。类别编号之间没有距离语义。
- 单调递减于p
- p越大损失越小、p = 1 时损失为0————把概率推得越高就被奖励越多,方向和“预测正确”完全一致。
- 错得越自信、惩罚越爆炸
时损失应该 ,给模型一个强烈的纠错信号————不能“完全错”和“差一点错”惩罚一样。这条是 MSE在分类上栽跟头的关键。
- 多样本可加
个独立样本的总损失最好写成 的形式,便于求和、平均和反传。概率连乘 容易发生数值下溢,取对数后可转换为求和。
熵(Entropy) = 一个分布的“不确定性”
想搞清楚一件事,平均需要多少“信息量”。
- 公平硬币(50/50):完全猜不透 --> 熵很大
- 作弊硬币(99/1):几乎没悬念 --> 熵很小(100%时熵=0)
💡 通俗理解:交叉熵
交叉熵衡量使用预测分布
它不是严格意义上的对称“距离”。因为
二分类交叉熵(BCE)
这是图片内容转换后的Markdown文本:
标签一确定,就有一项被乘 0 关掉,另一项被乘 1 留下,所以同一时间永远只有一项在算损失:
| 真实标签 | 公式坍缩为 | 含义 |
|---|---|---|
🔍 展开查看:BCE 与 Sigmoid 的梯度为何简洁
BCE + Sigmoid 一路链式算到z(Sigmoid之前的logit):
没有
- Sigmoid 导数
,恰好被交叉熵分母里的 整体约分掉了。 - Sigmoid 与 BCE、Softmax 与多分类 CE 在代数和概率建模上高度匹配;使用融合 logits 的实现还能提升数值稳定性。
🔍 展开查看:Softmax 与多分类交叉熵推导
比如 3 类任务下,网络给出
① softmax:把 logits 变成概率
用 softmax 处理一下,保证每项非负、且加起来等于 1,得到合法概率分布:
例如:
② 套 CE:求和坍缩到正确类
假设真实类别是第 0 类,one-hot 标签
反传到 logits 的梯度,和 BCE 一样干净(softmax 导数刚好和 CE 的 log 互相约掉):
损失函数选型总结
- 输出:不受限的连续预测值。
- 常用 API:
nn.MSELoss()。 - 统计解释:固定方差高斯噪声下的负对数似然,与 MSE 仅差常数和比例。
🔍 展开查看:代码实现
import torch
import torch.nn as nn
# ============ 回归: MSE ============
criterion = nn.MSELoss() # 默认 reduction='mean'
loss = criterion(pred, target) # pred, target 同形状的浮点张量
# ============ 二分类: BCE ============
# 推荐用 BCEWithLogitsLoss—输入是 logits (Sigmoid 之前),数值更稳
criterion = nn.BCEWithLogitsLoss()
loss = criterion(logits, target.float()) # target 是 0/1 浮点
# ============ 多分类: CrossEntropyLoss ============
# 关键: 输入是 logits (softmax 之前!),不是概率
criterion = nn.CrossEntropyLoss()
loss = criterion(logits, target.long()) # target 是 LongTensor,存类别下标 (不是 one-hot)2.3 反向传播:用链式法则分配误差
反向传播不是独立于链式法则的新求导规则,而是对计算图应用反向模式自动微分:从标量损失出发,按拓扑逆序复用局部导数,高效得到所有参数梯度。
假设一层满足
⚡ 避坑指南:梯度默认会累积
PyTorch 的 loss.backward() 会把新梯度累加到 .grad。常规训练应在下一次反向前调用 optimizer.zero_grad();只有梯度累积训练才故意延迟清零。
完整数值示例见手算与 PyTorch 自动微分。
2.4 梯度下降:沿负梯度更新参数
💡 通俗理解:蒙眼下山
想象自己被蒙着眼丢在一座山上,目标是走到山谷最低点。
- 没有地图,只能用脚感受坡度。
- 判断当前位置哪个方向最陡。
- 朝那个方向迈一小步。
- 再重新感受、再迈一步。
就这么循环,直到走不动了————这就是梯度下降。
梯度
多维损失函数
- 梯度指向
在当前点 处上升最快的方向;取负号————就是下降最快的方向。
2.4.1 参数更新公式
把“朝负梯度方向迈一步”写成公式:
:第t步的参数(当前位置)。 :当前位置的梯度方向(脚下最陡的方向)。 :步长 / 学习率,控制每一步迈多远。
搬到神经网络:维度爆炸但规则不变
是所有参数的集合(上亿维向量)。 是L对每个参数的偏导构成的向量,通过反向传播算出来。 - 更新规则
这里的
是整个训练过程最敏感的超参数————太大会震荡甚至发散,太小则进展缓慢。
后面会专门展开,先记住它的存在,以及不同优化器为它省心所做的种种巧妙设计。
2.5 优化器:如何走得又快又稳
为什么需要各种各样的优化器?
公式
用多少样本?
一次更新要不要用全部样本?怎么走步?
在窄长山谷里参数反复横跳怎么办?学习率要分配?
不同参数对学习率的敏感度差异巨大,要不要让它们各自调?要变化? 该不该随训练过程自动调整?
💡优化器的演化,本质上就是一代代研究者围绕这一行公式,不断回答上面这些问题:改梯度怎么算、改步子怎么迈、改学习率怎么分配。
Batch GD
1847年法国数学家柯西在研究彗星轨道时,提出人类历史上最早的梯度下降思想————面对六个未知数和一组高度非线性的方程,找不到解析解,只能沿着目标函数下降最快的方向一步步逼近。
Batch GD:每次都用全部样本
每次更新使用全部
在第t步更新时,模型先遍历完整个训练集,计算所有样本损失的平均梯度,再执行一次更新。
优势:
- 方向准确:每步沿全数据真实梯度,几乎无噪声。
- 理论性质好:凸优化下学习率合适即有较好收敛保证。
代价:
- 训练成本高:一次更新就要跑完全部数据,模型往往要很久才能走出几步。
- 缺少随机性:进入鞍点或梯度小的区域,没有噪声扰动来跳出去。
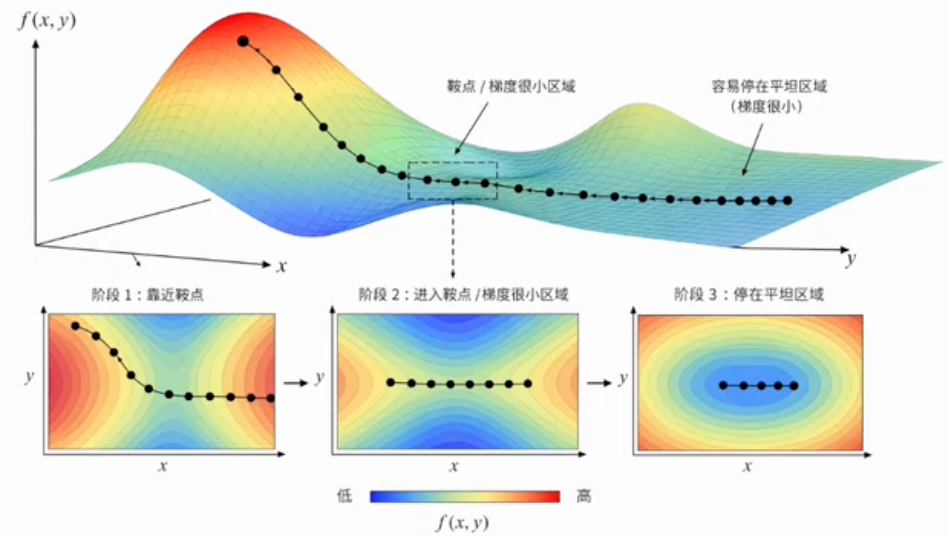
Batch GD 用更高计算成本换取精确、稳定的全数据梯度。在小数据集和经典凸问题中仍有价值;在大型深度学习任务中,通常因更新频率和内存成本而不实用。
SGD
1951年北卡罗来纳大学的两位统计学家在研究小白鼠用药问题:每次只能观察到一个带随机波动的反应,如何估计出让50%个体产生反应的剂量?
他们提出的随机逼近思想很朴素:既然每次只有一个带噪声的观测,那就用它做一次小幅调整————长期来看依然能逼近真实答案。
SGD(Stochastic Gradient Descent):
第t次更新不再用全集平均,而是随机抽一个样本,用它的梯度作为整体梯度的估计。
优势:
- 计算成本骤降:每步从O(N)降到O(1),效率提升几个数量级。
- 扰动平坦区与鞍点:单样本梯度带有噪声,有时能帮助参数离开鞍点或平坦区域,但不保证跳出所有局部最优。
- 支持在线学习:数据可一条条流入,边接收边更新。
代价:
- 剧烈震荡:单样本方差大,参数在最优点附近来回摆动,难以稳定收敛。
- 学习率需衰减:固定可能永远震荡;衰减过快又过早停在次优位置。
- 对离群样本敏感:一个异常样本就可能把参数拉向奇怪方向。
💡今天很少用纯单样本SGD,但“用随机子样本近似全样本梯度”这一核心思想,已经是现代深度学习优化方法的基石。
Mini-batch SGD
90年代研究者意识到:一个样本太抖、全体样本太慢。
Mini-batch SGD:工程上的甜点
每次随机抽取大小为
优点:
- 方差显著降低:在样本近似独立等条件下,batch 内梯度平均的方差大致按
缩小,比单样本 SGD 稳定。 - GPU友好:batch内可并行前向反向,充分利用向量化————这是Mini-batch在深度学习时代的杀手锏。
- 保留适度随机性:比Batch GD仍有噪声助力跳鞍点;比单样本SGD又不至于剧烈震荡。
代价:
- Batch size是关键超参
- 太小:噪声大、收敛慢。
- 太大:逐渐逼近Batch GD,梯度过精确,可能降低泛化能力。
- 大batch需要匹配大学习率:否则更新幅度过小,等价于有效训练步数不足————这也是大规模训练常用学习率预热、线性放大的原因。
💡Mini-batch SGD在统计效率(降方差)与计算效率(用满硬件)之间找到极具工程价值的平衡点。如今深度学习语境下,SGD默认就是指Mini-batch SGD,几乎所有优化器都在它的框架上做改进。
Momentum
1964年
苏联数学家Boris Polyak 在研究迭代法收敛速度时提出动量法。
核心思想:不要只看当前这一步的梯度,把过去几步的运动趋势也考虑进来————方向一致的更新被持续强化,来回震荡的更新则被逐步抵消。

Momentum:给梯度下降装上惯性
维护一个速度向量
是动量系数,常见起点为 ,仍应结合任务验证。
- 加速一致方向:连续几步梯度方向相近 ->
累积 -> 越走越快。 - 抑制震荡方向:谷地中横向左右摆动 -> 相反方向相互抵销 -> 把更新留给真正前进方向。
- 穿越浅鞍点与平台区:即使瞬时梯度接近0,凭已积累的速度仍能继续前进。
代价:
- 可能冲过头:参数接近最优点时,速度仍较大就可能越过最低点,再折返回来————表现为最优点附近的小幅震荡。
- 对
有敏感性: 太小积累不明显,太大又可能让系统迟钝甚至难以控制————多数实践中0.9几乎是稳妥默认值。
SGD + Momentum 是训练 VGG、ResNet 等经典 CNN 的重要方案,至今仍很常用;但是否优于 AdamW 取决于模型、数据、训练预算与调参质量。
AdaGrad
出发点:不同参数的梯度大小差异悬殊,用同一个学习率更新所有参数过于简单粗暴。
解决思路:给每个参数单独维护一个历史梯度积累量,用它来自适应地调整这个参数的有效学习率。
NLP里的痛点例子
- "the":高频词,几乎每个batch都出现,对应参数梯度很大、更新已经很充分。
- "serendipity":低频词,整个训练里只出现寥寥几次,梯度极小。
- 同一学习率下,低频词参数几乎永远学不动。
AdaGrad:分母累加梯度平方
- 梯度大、更新频繁的参数:
累积得很大 -> 有效学习率缩小————避免更新过度。 - 梯度小、更新稀少的参数:
累积得很小 -> 有效学习率保持较大————保证仍能被充分学习。
💡“对历史更新多的参数降速、对历史更新少的参数提速”————这就是自适应学习率的核心思想,AdaGrad是开山之作。
优势:
- 按参数自适应缩放:每个参数的有效步长由历史梯度决定,但全局学习率
仍需要选择。 - 天然适合稀疏数据:低频特征不会因梯度小被忽视,在NLP/推荐系统中尤其显著。
劣势:
只累加、从不减小。 - 训练越久,分母越大,有效学习率单调趋近于0。
- 模型还没充分收敛就已经动弹不得,深层网络尤其明显。
💡正是这个缺陷,催生了后来的RMSProp和Adam————它们的核心改进都指向同一件事:不要让历史梯度无限积累,只保留近期梯度的影响。
RMSProp
2012是AlexNet引爆深度学习的年头。网络越来越深、训练越来越久,研究者迫切需要比AdaGrad更适合长期训练的自适应方法。
改进思路非常直接:不要把训练以来的所有梯度平方都加起来,只保留近期的梯度信息————这就是RMSProp的核心思想。
RMSProp:用滑动平均修补AdaGrad
优势:
- 不再衰减到0:滑动平均会逐渐遗忘久远的梯度,分母不再无限膨胀。
- 保留自适应优势:每个参数仍有独立的更新尺度————梯度大的自动缩、稀疏的保持大。
- 适合非平稳目标:深度学习的loss曲面会变化,RMSProp只关注近期梯度,更能适应动态环境。
劣势:
- 基础 RMSProp 公式只维护梯度平方的滑动平均,没有 Adam 那样显式维护一阶矩;部分框架实现可额外启用
momentum。 - 多了个超参数
:实践中0.9已经足够好用,但本质上仍然增加了调参空间。
💡RMSProp在训练RNN时尤其受欢迎————RNN的损失曲面更崎岖,AdaGrad那种越训越小、最后停住的死法在这里特别难以接受。
RMSProp一度成为循环神经网络训练的常用选择————直到2015年Adam出现。
Adam
到2014-2015年,深度学习优化方法已经形成两条清晰的思路:
- AdaGrad / RMSProp路线:利用梯度平方的二阶信息,为不同参数自适应地调整学习率。
- Momentum路线:利用历史梯度的一阶信息,积累速度————正确方向上加速、震荡方向上减速。
💡既然各有所长,为什么不把它们合起来?这正是2014年Diederik Kingma 和 Jimmy Ba 提出的Adam(Adaptive Moment Estimation)的出发点————既要方向感,又要步长感。
🔍 展开查看:Adam 的完整更新公式
- 计算梯度:
- 更新一阶矩估计(梯度的指数移动平均):
- 更新二阶矩估计(梯度平方的指数移动平均):
- 计算偏差校正后的一阶矩(修正初期
偏向于 0 的问题):
- 计算偏差校正后的二阶矩(修正初期
偏向于 0 的问题):
- 更新参数:
:一阶矩和二阶矩的指数衰减率(通常默认为 和 ) :为了数值稳定性而添加的一个极小常数(通常取 )
💡偏差校正(bias correction):因为
优势:
- 像Momentum:引入惯性————参考历史梯度让更新方向更平滑,不容易被局部噪声带偏。
- 像RMSProp:自适应缩放————为每个参数单独定制步长,频繁更新的自动收缩、稀疏的保持稳健。
- 偏差校正稳住初期:避免冷启动阶段的步长过小,让模型从一开始就高效推进。
💡Adam 通常具有较好的开箱体验和较快的初期收敛,但仍对全局学习率、
AdamW
研究表明,在 Adam 中把 L2 惩罚直接加进梯度,并不等价于对参数执行统一的解耦权重衰减。
- SGD的旧设:在传统SGD中,权重衰减
L2正则化,所以早期Adam直接把L2项加进梯度里。 - Adam里出了问题:本该稳定的正则信号被自适应机制一同缩放————梯度大的参数衰减不足、梯度小的过度衰减,正则化效果完全偏离原意。
💡2017年Ilya Loshchilov等人提出AdamW,把梯度更新和权重衰减彻底拆开。
AdamW的更新公式
新增的
这一修正让正则化含义更清晰,也便于独立调节权重衰减。AdamW 已成为 Transformer、ViT 和许多语言模型训练中的常见默认选择,但具体优化器仍应依据架构与验证实验确定。
Muon
2024年
Adam / AdamW 把每个标量参数当作独立维度处理。
Muon换了视角————神经网络里真正的主角是二维权重矩阵。
在Momentum之上,对更新矩阵做一次Newton-Schulz迭代近似SVD正交化————把奇异值拉平后再走一步。
Muon:针对二维权重W的公式骨架:
效果:让所有奇异方向获得均衡的更新幅度,避免少数大奇异值方向主导整步。
Muon 已在部分语言模型训练实验中展示出潜力,但它仍是快速演进中的方法。相对 AdamW 的收益取决于模型结构、参数分组、实现细节和算力环境,不能脱离受控基准直接下结论。
优化器总结
优化器的演化路线:
每一次改进背后都有同一个问题在驱动:怎么让参数更新得又快又稳?
- 常用于 CNN 等从头训练任务。
- 需要更认真地选择学习率和调度器。
- 在部分任务上可获得很好的最终泛化,但收敛初期通常慢于 Adam 系列。
2.6 手算与 PyTorch 自动微分
神经网络学习的本质:
前向传播 算误差 --> 反向传播 算梯度 --> 梯度下降 更新参数 --> 再次前向传播 .....
- 如此循环多轮,并使用验证集监控泛化表现。训练损失接近
并不代表模型已经训练好,它也可能意味着严重过拟合。
神经网络设计:
目标t:0
网络结构:[1, 1, 1, 1]
激活函数:ReLU
损失函数:MSELoss
优化器:SGD
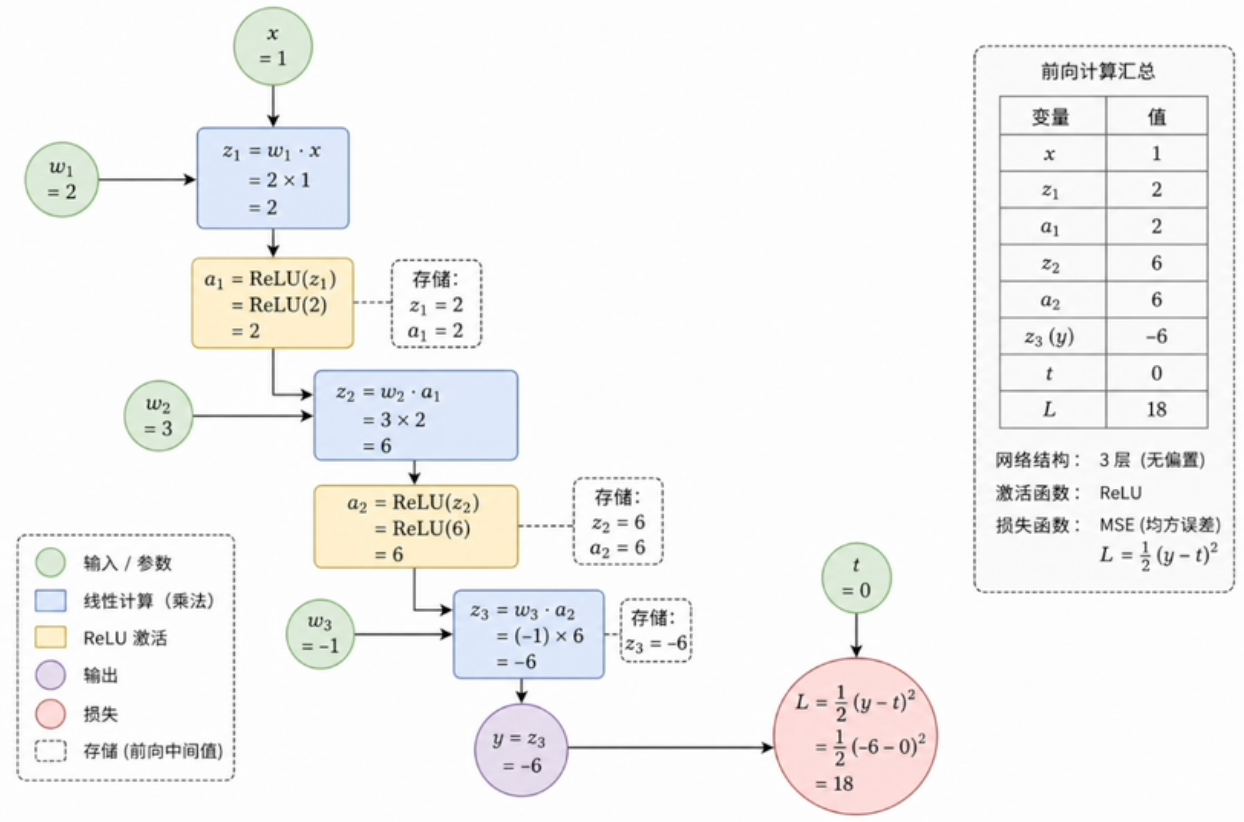
- 预测值为
,目标为 。图中采用 ,因此损失为 ;后续 PyTorch 默认 MSE 不含 。
反向传播: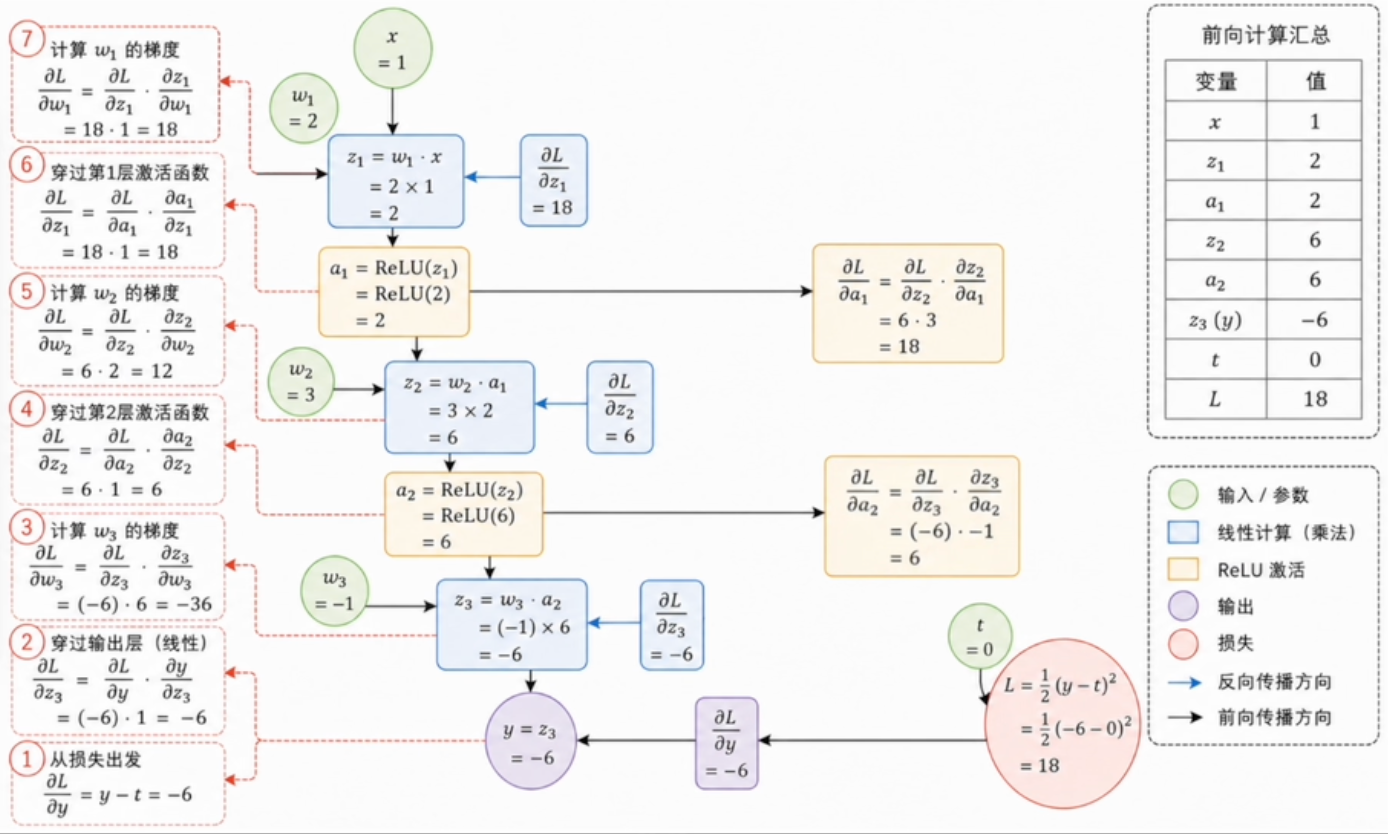
用梯度下降更新参数:
设学习率
| 参数 | 旧值 | 梯度 | 更新量 | 新值 |
|---|---|---|---|---|
| 2 | 18 | 1.82 | ||
| 3 | 12 | 2.88 | ||
| -1 | -36 | -0.64 |
用PyTorch实现:自动微分的优雅
只需写出前向公式,PyTorch会在后台自动构建计算图,再用一行loss.backward()把所有梯度一次算出来。
🔍 展开查看:代码实现
import torch
import torch.nn as nn
# 数据
x = torch.tensor([[1.0]]) # 输入1
t = torch.tensor([[0.0]]) # 预测结果0
# 网络
model = nn.Sequential(
nn.Linear(1, 1, bias=False), # w1
nn.ReLU(),
nn.Linear(1, 1, bias=False), # w2
nn.ReLU(),
nn.Linear(1, 1, bias=False), # w3
)
# 初始化权重,与上面手算示例保持一致
with torch.no_grad(): # 关掉梯度后初始化权重
model[0].weight.fill_(2.0)
model[2].weight.fill_(3.0)
model[4].weight.fill_(-1.0)
# 损失函数 + 随机梯度下降优化器
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练100轮
for epoch in range(100):
loss = criterion(model(x), t) # 前向传播 + 计算损失
optimizer.zero_grad() # 清空上一轮残留的梯度
loss.backward() # 反向传播,自动计算梯度
optimizer.step() # 梯度下降更新权重
if epoch % 10 == 0:
print(f"Epoch {epoch+1:3d} | 预测值: {model(x).item():7.4f} | 损失: {loss.item():.4f}")注意:PyTorch的nn.MSELoss()默认是
3. MNIST 实战:从手写参数到 nn.Module
3.1 数据集与预处理
MNIST是28x28的灰度手写数字图,0-9共10类。训练集60000张,测试集10000张。是深度学习界的"Hello World"。
训练集:60000 张
测试集:10000 张
每张图:torch.Size([1, 28, 28])(通道 x 高 x 宽)查看前九个样本

3.2 网络结构与参数量
两层MLP设计:784 -> 128 -> 10
输入层(784):把28x28灰度图展平为784维向量————每个像素是一个特征。
隐层(128):
输出(10):
参数量:
总参数量为
3.3 手写训练循环与 nn.Module
PyTorch训练循环的四个动作
- forward:前向计算
- loss:算预测和真值差距
- backward:链式法则算每个参数的梯度
- step:沿梯度反方向更新参数
- 初始化4个参数张量
🔍 展开查看:代码实现
# 手动初始化4个参数张量:W1, b1, W2, b2
# 单独重跑这一段时,再固定一次种子,让权重初始化可复现
torch.manual_seed(42)
# requires_grad=True:告诉autograd“这个张量是参数,需要记录梯度”
# 没有这个标记,loss.backward() 算不出p.grad
#
# (2.0 / n_in) ** 0.5 是 He 初始化的标准差,专门给ReLU网络用
W1 = (torch.randn(784, 128) * (2.0 / 784) ** 0.5).requires_grad_()
b1 = torch.zeros(128, requires_grad=True)
# 第二层:128 -> 10(输出10个类别的logits)
W2 = (torch.randn(128, 10) * (2.0 / 128) ** 0.5).requires_grad_()
b2 = torch.zeros(10, requires_grad=True)
# 把 4 个参数放一个列表里,后面统一更新
params = [W1, b1, W2, b2]
lr = 0.1 # 学习率:每次梯度下降迈多大一步。
print(f'网络共 {sum(p.numel() for p in params):,} 个参数')requires_grad:没这个标记,loss.backward()算不出p.grad。这是张量“是不是参数”的标识。- He初始化:
sqrt(2/n_in)是ReLU网络的经验值。
⚡ 避坑指南:确保参数是叶子张量
torch.randn(..., requires_grad=True) * scale 会因乘法产生非叶子张量,导致其 .grad 默认不被保留。本例先完成缩放再调用 .requires_grad_(),因此
- 四步训练循环
🔍 展开查看:代码实现
for epoch in range(5):
running_loss = 0.0 # 累积本epoch所有batch的loss * 样本数,最后求平均
n_samples = 0
for xb, yb in train_loader:
# xb 形状 (128, 1, 28, 28), yb 形状 (128,)
# 我们的网络只识别1D向量,所以把图像拍平成(128, 784)
x = xb.view(-1, 784)
# 1. forward: 「线性 + 非线性」的组合
h = F.relu(x @ W1 + b1) # 隐藏层:内层线性变换,然后使用非线性函数ReLU激活
logits = h @ W2 + b2 # 输出层:只做线性变换,不加softmax
# (CrossEntropy内部会做log_softmax,自己加反而数值不稳)
# 2. loss: 算预测和真值的差距
# cross_entropy接收logits(为归一化的分数)和整数标签,自动做softmax + 交叉熵
loss = F.cross_entropy(logits, yb)
# 3. backward: 反向传播
# autograd 顺着前向那条计算图,从loss一路链式求导回每个requires_grad的张量
# 求出来的梯度自动累加到p.grad(所以下面要记得清零)
loss.backward()
# 4. step: 梯度下降,沿梯度反方向更新参数
# 参数更新本身不需要建图(不需要对“更新这一步”再求导),所以包在no_grad里
with torch.no_grad():
for p in params:
p -= lr * p.grad # 沿梯度反方向迈lr这么大一步
p.grad.zero_() # 清零,防止下个batch的梯度叠加起来- 输出层不加softmax:
F.cross_entropy内部会做log_softmax。自己再加一层softmax反而数值不稳。 view(-1, 784)展平:网络只识别1D向量。MLP看不见28x28的空间结构。with torch.no_grad():参数更新本身不需要建图(不需要“对更新这一步再求导”)————包进no_grad省内存、防误算。p.grad.zero_()必须手动:PyTorch默认梯度累加。不清零,下个batch的梯度会叠加进来————常见bug。loss.backward()做了什么:从loss顺着前向那条计算图一路链式求导,把每个requires_grad张量的梯度算出来累加到.grad。
nn.Module版
🔍 展开查看:代码实现
class SimpleMLP(nn.Module):
"""两层MLP:784 -> 128 -> 10
继承nn.Module之后,PyTorch自动管理:
- 把self.fcN 里的参数收集起来(module.parameters())
- .train() / .eval() 自动切换 Dropout 、BN 等层的行为
- .to(device) 把所有参数搬到GPU
"""
def __init__(self):
super().__init__()
# nn.Linear(in, out) 一行同时帮我们造好W(out x in)和b(out)
# nn.Linear 使用基于 fan_in 的均匀初始化,但并不等同于标准 He normal
self.fc1 = nn.Linear(784, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = x.view(-1, 784) # 展平为(batch, 784)
x = F.relu(self.fc1(x)) # 隐层 + ReLU
return self.fc2(x) # 输出logits(不加softmax)
torch.manual_seed(42)
model = SimpleMLP()
optimizer = optim.SGD(model.parameters(), lr=0.1) # SGD内部就是手写版的`p -= lr * p.grad`
loss_fn = nn.CrossEntropyLoss() # 等价于F.cross_entropy
train_losses_v2 = []
test_accs_v2 = []
for epoch in range(5):
model.train() # 进入训练模式
running_loss = 0.0
n_samples = 0
for xb, yb in train_loader:
optimizer.zero_grad() # 代替手写版的`p.grad.zero_()`,一行清掉所有参数的梯度
logits = model(xb) # 1. forward ———— 等价于 model.forward(xb)
loss = loss_fn(logits, yb) # 2. loss
loss.backward() # 3. backward ———— 还是 autograd 在做事
optimizer.step() # 4. step ———— 代替手写版的 `p -= lr * grad`
running_loss += loss.item() * yb.size(0)
n_samples += yb.size(0)
model.eval() # 进入评估模式
correct = 0
with torch.no_grad():
for xb, yb in test_loader:
correct += (model(xb).argmax(1) == yb).sum().item()
train_losses_v2.append(running_loss / n_samples)
test_accs_v2.append(correct / len(test_set))
print(f'epoch {epoch+1}/5 train_loss={train_losses_v2[-1]:.4f} test_acc={test_accs_v2[-1]:.4f}')
# 教学代码为了简洁逐轮展示 test_acc;真实项目应从训练集划出验证集,
# 用验证集调参和早停,测试集只在方案冻结后做最终评估。⚡ 避坑指南:不要逐轮窥视测试集来调参
上面的 test_acc 只为演示接口。真实项目应建立验证集,用验证指标选择 epoch、结构和超参数;测试集只在方案冻结后用于最终评估。
3.4 交互式手写数字识别

4. 训练稳定性与泛化工程
4.1 学习率与调度器
神经网络的参数大部分通过梯度下降自动学得。还有一类参数需要训练前手动设定————学习率、batch size、epoch数、隐藏层维度、激活函数等,称为超参数(hyperparameter)。
其中学习率(learning rate,lr)通常被认为是最重要、也最敏感的一个:量级设错,模型完全训不起来;量级对了但不会动态调整,最终精度也会被压死在一个上限。
💡Adam、AdamW这些自适应优化器只在参数之间做相对步长的微调。全局学习率
学习率设置
训练周期与学习率
训练初期:
参数随机初始化,梯度大且方向不稳。先用较小的lr试探“地形”,让模型进入合理的优化区域。训练中期:
已经进入稳定下降阶段,可以用相对较大的lr,加快向较优解靠近的速度。训练后期:
参数接近最优点,把lr逐步调小,以更细的步伐做精修,提高最终精度。
常用组合是 Warmup + Cosine !!!
下面介绍一些常见的调度器
线性Warmup
预热(Warmup)的思路很直接:训练最开始的若干步内,让学习率从一个很小的值逐步上升到目标值,给优化器一段预热时间,参数和动量估计稳定下来后再正式大步前进。
线性预热(Linear Warmup):
其中
- 按步数设置:例如「前1000步预热」,与batch size 和数据集大小解耦,跨任务迁移方便。
- 按比例设置:例如「总步数的5%-10%」,更直观,能随总训练量自动调整预热长度。
🔍 展开查看:代码实现
from torch.optim.lr_scheduler import LinearLR
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
# 从目标学习率的千分之一开始 warmup
warmup_scheduler = LinearLR(
optimizer, start_factor=1e-3, end_factor=1.0, total_iters=warmup_steps
)
# 本例 warmup_steps 按 batch 数定义,因此每个 batch 后调用 scheduler.step()固定学习率VS线性Warmup
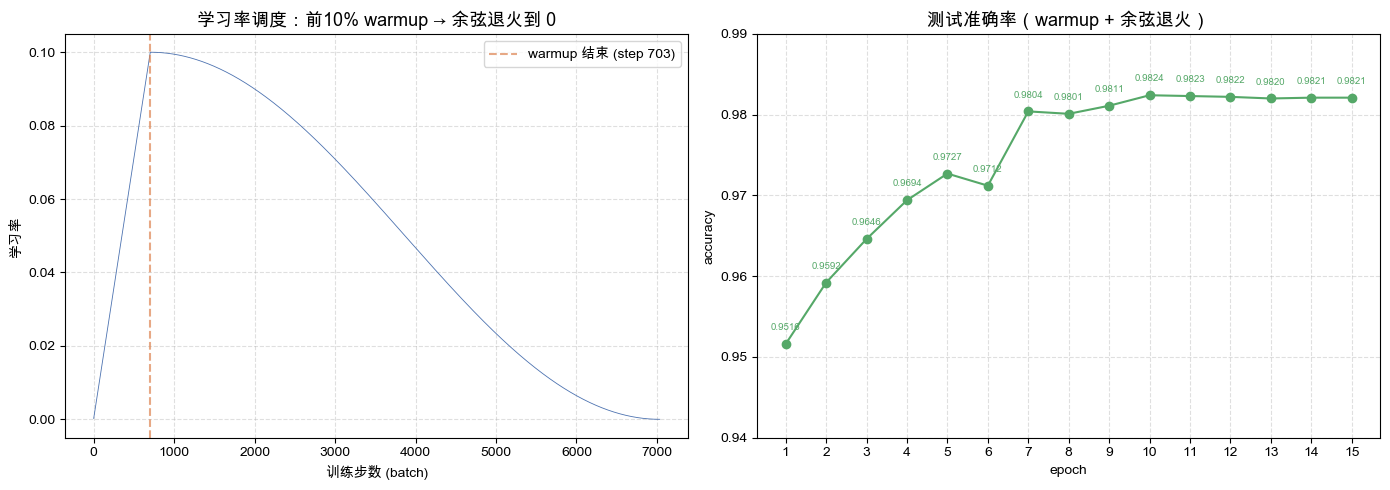
4层MLP(784->256->256->256->10) + Adam(lr=0.02),MNIST 5 epoch。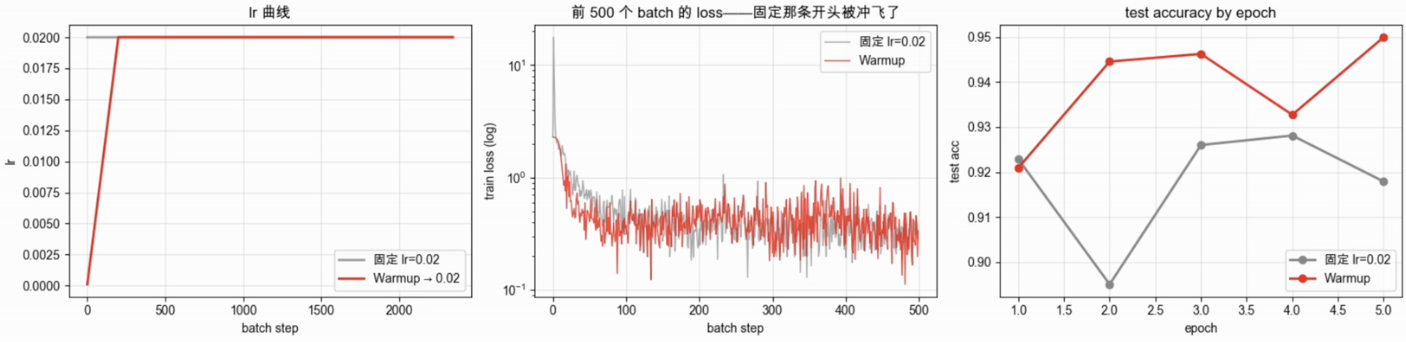
❌ Adam(lr=0.02)直接上
前 50 batch 最大 loss=17.73;5 epoch后 test_acc=91.75%
前几步样本太少,二阶矩
✅ + 200-step线性warmup
前 50 batch 最大 loss=2.30;5 epoch后 test_acc=94.74%
前 200 batch 的 lr 仍然很小,给 Adam 一段时间累积可靠的
Step/MultiStep decay
预热结束后进入收敛阶段,什么时候降、降多少,可以通过Step/MultiStep来控制。
Step decay:固定间隔衰减
每过一个间隔
from torch.optim.lr_scheduler import StepLR
optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
scheduler = StepLR(optimizer, step_size=3, gamma=0.5)
# scheduler.step() 使用方法:推荐per-epochMultiStep decay:自由制定节点
不再等间隔,手动指定一组节点
from torch.optim.lr_scheduler import MultiStepLR
optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
scheduler = MultiStepLR(optimizer, milestones=[30, 60, 80], gamma=0.5)
# 使用方法:推荐per-epoch共同问题:衰减节奏是固定的,不能根据实际的损失情况自适应调整。
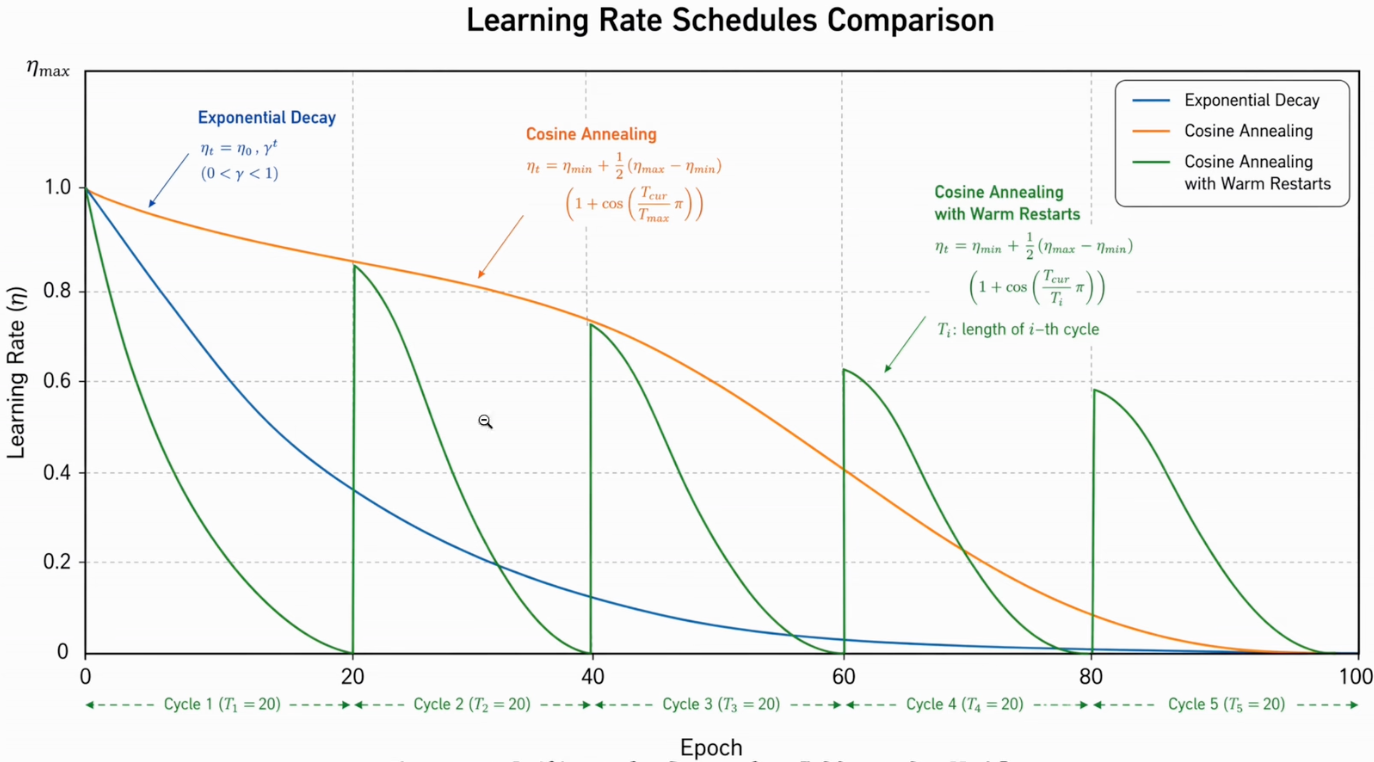
Exponential decay
指数衰减:
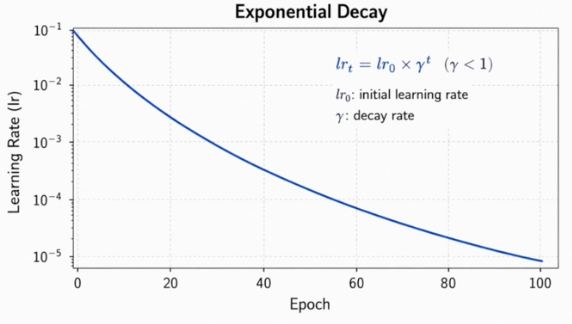
- 对
极度敏感 - 若每个 epoch 乘固定
,其相对衰减比例恒定;在普通线性纵轴上呈现前期绝对降幅大、后期绝对降幅小。是否合适取决于任务。
from torch.optim.lr_scheduler import ExponentialLR
optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
scheduler = ExponentialLR(optimizer, gamma=0.95)
# scheduler.step() 使用方法:per-epochCosine Annealing
余弦退火 借用余弦函数的形状控制学习率,从t = 0 到t = T沿半个余弦周期平滑下降:
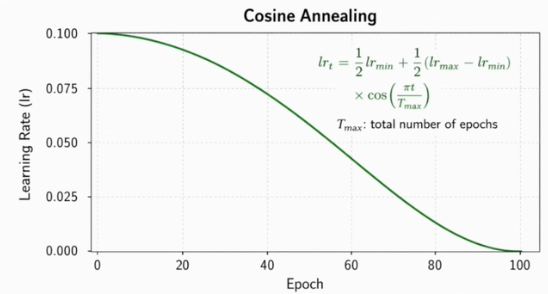
- 前期慢:lr较大但下降缓慢,模型在较大范围内探索参数空间。
- 中期快:lr快速下降,加速向较优区域收敛。
- 后期慢:lr已经很小,下降也再次放缓,精修不会因步长突变而震荡。
from torch.optim.lr_scheduler import CosineAnnealingLR
optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
# T_max 设为 总训练epoch数,eta_min 设为 最小学习率
scheduler = CosineAnnealingLR(optimizer, T_max=100, eta_min=1e-6)
# 本例 T_max 按 epoch 定义,因此每个 epoch 结束后调用 scheduler.step()💡相比指数衰减前期跌太快、Step decay 阶梯跳变,余弦退火的曲线更加平滑自然。2017年提出后迅速成为单段训练的默认选择。
SGDR:带重启的余弦退火
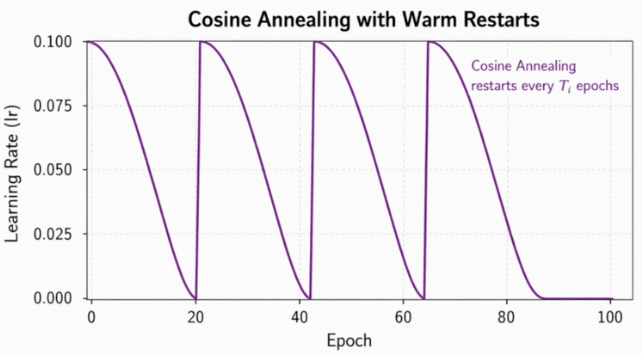
- 重启:周期开始时学习率回升,可增加探索性;它可能帮助离开当前区域,但不保证一定找到更优解。
- 周期可逐渐拉长:常见做法是
T_mult=2,每次周期翻倍————前期快速探索,后期充分收敛。
from torch.optim.lr_scheduler import CosineAnnealingWarmRestarts
optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
# T_0 是第一个退火周期的长度, T_mult 是每次重启后周期的倍增系数
scheduler = CosineAnnealingWarmRestarts(optimizer, T_0=20, T_mult=2, eta_min=1e-6)
# 若按 batch 更新,可传入 epoch + batch_idx / batches_per_epoch 作为进度指数vs余弦退火
ReduceLROnPlateau
ReduceLROnPlateau:按效果调度
🔍 展开查看:代码实现
from torch.optim.lr_scheduler import ReduceLROnPlateau
optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
scheduler = ReduceLROnPlateau(
optimizer,
mode='min', # 监控指标越小越好 (如 loss)
factor=0.5, # 触发时 lr *= 0.5
patience=5, # 连续 5 轮无改善才触发
min_lr=1e-6, # lr 下限
)
for epoch in range(100):
train(...)
val_loss = evaluate(...)
scheduler.step(val_loss)
# !关键差异:必须把监控指标传进去- ✅核心优势:不依赖先验知识
- ⚠️依赖验证集:必须定期评估验证集;大模型训练下开销不可忽视。
- ⚠️响应滞后: patience 机制必要,但意味着lr调整总是滞后于模型实际状态。
- ⚠️只降不升:lr一旦降下就不会回头,无法像SGDR那样跳出局部极小。
余弦退火 vs ReduceLROnPlateau
- 按训练步数预先规划,过程可复现且无需等待指标触发。
- 适合总步数明确的大规模训练,常与 Warmup 组合。
- 仍需通过验证指标确认计划是否合理,不能默认适用于所有任务。
Warmup + Cosine 应用
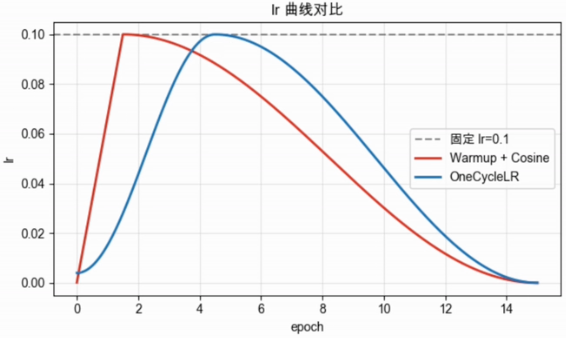
OneCycleLR
Leslie Smith 在 2017 年提出 1cycle 策略:按 batch 让学习率先升至峰值、再降至很小,并通常反向调整动量。合适的峰值学习率下,它可能缩短训练时间;峰值设置不当仍会发散。
🔍 展开查看:代码实现
from torch.optim.lr_scheduler import OneCycleLR
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# 总step数 = epoch数 x 每个epoch的batch数
total_steps = epochs * len(train_loader)
scheduler = OneCycleLR(
optimizer,
max_lr=0.1, # 学习率峰值(也可为每个参数组提供列表)
total_steps=total_steps, # 总训练步数(batch 数),None 时用 epochs * steps_per_epoch
epochs=None, # 训练轮数,和 total_steps 二选一
steps_per_epoch=None, # 每 epoch 的 batch 数,和 total_steps 二选一
pct_start=0.3, # 上升阶段占总步数的比例(默认 30%)
anneal_strategy='cos', # 退火策略:'cos'(余弦) 或 'linear'(线性)
cycle_momentum=True, # 是否同步循环动量(仅 SGD/Adam 类有 momentum 的优化器)
base_momentum=0.85, # 动量下界(max_lr 时用最小动量,min_lr 时用最大动量)
max_momentum=0.95, # 动量上界
div_factor=25.0, # 初始 lr = max_lr / div_factor
final_div_factor=10000.0, # 最终 lr = 初始 lr / final_div_factor = max_lr / (div_factor * final_div_factor)
three_phase=False, # True 时:上升 → 下降 → 极小平台(各 1/3);False:上升 → 下降
last_epoch=-1, # 断点续训用,一般不管
)- 学习率先升至峰值,再降到很小;通常同步反向调整动量。
- 强调在一个训练周期内完成探索与收敛。
- 必须按 batch 调用,并准确给出总训练步数。
调度器总结
StepLR / MultiStepLR / ExponentialLR 按固定规则衰减,简单可控,但需要事先知道合适的衰减节奏。
⭐ 调度器选型建议
- 总步数明确的大规模训练:优先从 Warmup + Cosine 开始。
- 验证成本可接受、训练长度未知:可以尝试 ReduceLROnPlateau。
- 固定预算的从头训练:OneCycleLR 值得实验,但不是所有 CV 任务的固定首选。
最终选择必须结合峰值学习率、batch size、优化器和验证曲线共同确定。
4.2 参数初始化
所有权重初始化产生的问题:
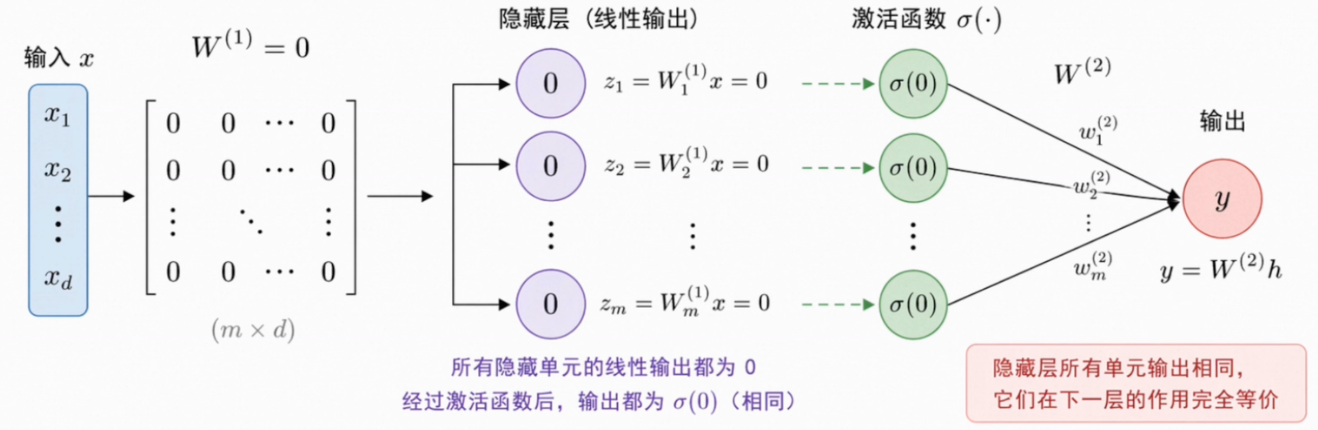
对称性问题(symmetry problem):同一层名义上的多个神经元始终在做同一件事,网络退化成重复拷贝的单元,再宽也没有意义。
💡把同一层权重初始化成任何一个相同常数,结果都一样————所以权重必须从一开始就被赋予互不相同的随机值。
Xavier 初始化
2010年Glorot & Bengio 提出Xavier 初始化,同时照顾前向激活和反向梯度的尺度稳定。
Xavier:前向权重方差和反向权重方差的折中
# Xavier 正态版
nn.init.xavier_normal_(linear.weight)
# Xavier 均匀版
nn.init.xavier_uniform_(linear.weight)Xavier 假设激活工作在近似线性区域,常与 Tanh 搭配。Sigmoid 在
He 初始化
2015 年何恺明团队提出 He (Kaiming) 初始化,既然 ReLU 会把方差削减一半,那就把权重方差加倍补回来。
He 初始化:
# He 正态分布初始化: std = sqrt(2 / fan_in)
nn.init.kaiming_normal_(linear.weight, nonlinearity='relu')
# He 均匀分布初始化
nn.init.kaiming_uniform_(linear.weight, nonlinearity='relu')⚡ 易混淆点:kaiming_* 的参数要与激活匹配
PyTorch 的 kaiming_* 默认写作 nonlinearity='leaky_relu' 且 a=0,此时 gain 与 ReLU 相同。为了表达真实意图并避免修改 a 后产生歧义,ReLU 网络仍建议显式传入 nonlinearity='relu';Leaky ReLU 则应同时传入对应负斜率。
PyTorch默认初始化
既然初始化这么重要,为什么平时直接 nn.Linear(...) 不调任何 init,模型也常常能训起来?因为 PyTorch 已经在背后做了一次。nn.Linear 的源码大致是:
def reset_parameters(self):
nn.init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = nn.init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in) if fan_in > 0 else 0
nn.init.uniform_(self.bias, -bound, bound)第一行调的是 kaiming_uniform_,但 a = sqrt(5) 把 gain 压成了
框架默认初始化是稳健起点,但不等于所有 ReLU 网络都应强制覆盖为 He Normal。深层网络还受到残差连接、归一化、激活函数和架构既定初始化方案影响,应遵循模型配方并通过实验验证。
初始化对比实验
使用 4 层 ReLU MLP(784→256→256→256→10)和 MNIST 数据集,在相同训练循环下仅更换权重初始化函数。该实验使用官方测试集展示曲线,适合教学观察,不应作为正式调参流程。
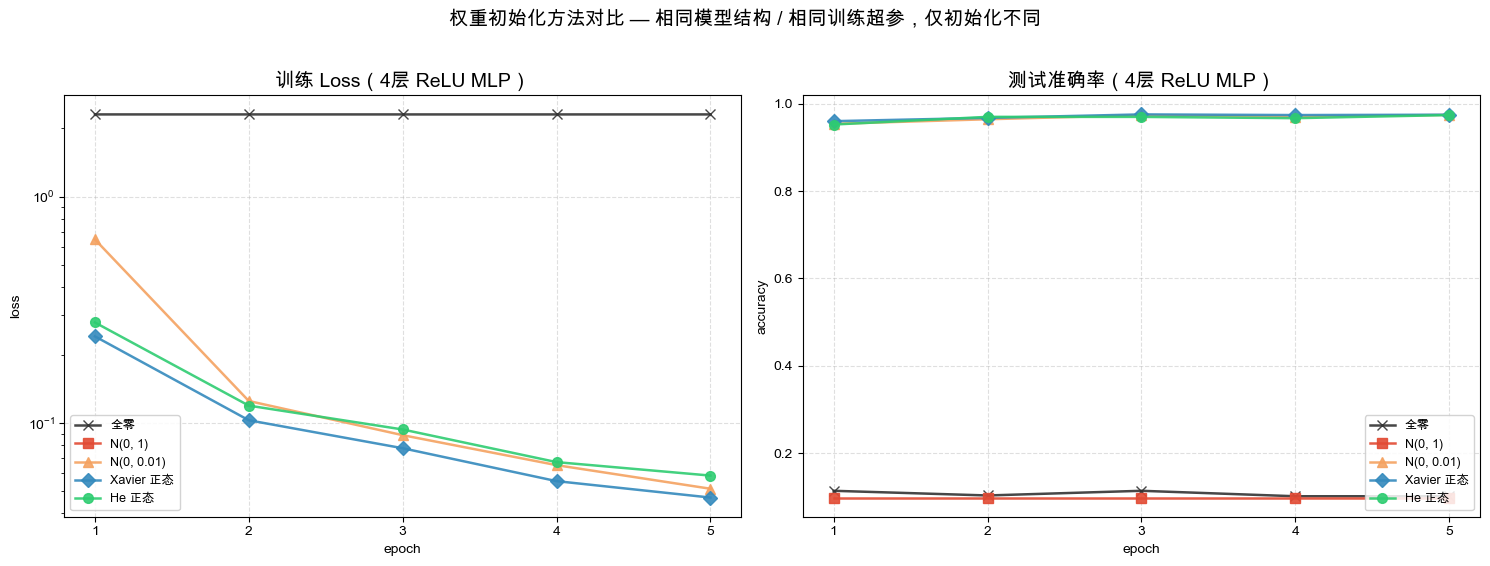
=======================================================
初始化方法 train_loss test_acc
----------------------------------------
全零 2.3033 0.1010
N(0, 1) nan 0.0980
N(0, 0.01) 0.0514 0.9745
Xavier 正态 0.0470 0.9749
He 正态 0.0587 0.9741
=======================================================
结论:全零和过大的初始化在本实验中明显失败;
Xavier、He 与较小正态初始化都能训练。
单次 5-epoch 结果不能证明某一种初始化普遍最优,
应比较多随机种子、梯度统计和最终验证指标。⚡ 实验结论的边界
单次随机种子、5 个 epoch 与测试集反馈不足以证明初始化方法的普遍优劣。正式实验应使用验证集选型、运行多个随机种子,并在配置冻结后只评估一次测试集。
参数初始化总结
参数初始化的目标不是随便给个随机数,而是让网络在训练一开始就处在一个信号尺度合理的状态。
① 打破对称:权重必须随机;同一层相同(不只是全0)就一定退化。
② 控制尺度:权重方差必须被精确缩放,否则深度本身就会把信号推向爆炸或归零。
③ 偏置可全 0:权重已随机就不再存在对称性问题;LSTM forget gate 这类是少数特例。
通常从 He / Kaiming 初始化开始,并让 nonlinearity 与真实激活函数一致。
4.3 归一化层
在不加归一化的情况下,深度神经网络非常难训练,主要有以下几个“致命伤”:
中间激活尺度变化:前层参数更新会改变后层输入分布与尺度,使优化更困难。“内部协变量偏移”是 BatchNorm 的经典直觉解释,但现代研究认为它并不是全部原因,损失曲面平滑化与参数化改善同样重要。
梯度消失与饱和:Sigmoid、Tanh 在输入绝对值较大时容易饱和。合适的归一化可让更多激活处在有效梯度区域,但不能单独解决所有梯度问题。Softmax 通常位于输出层,不应与隐藏层饱和问题混为一谈。
改善优化条件:特征尺度悬殊时,损失等高线可能高度拉伸,梯度下降容易震荡。输入标准化与网络归一化通常能改善条件数、允许更大学习率,但不会保证把复杂非凸地形变成理想圆形。
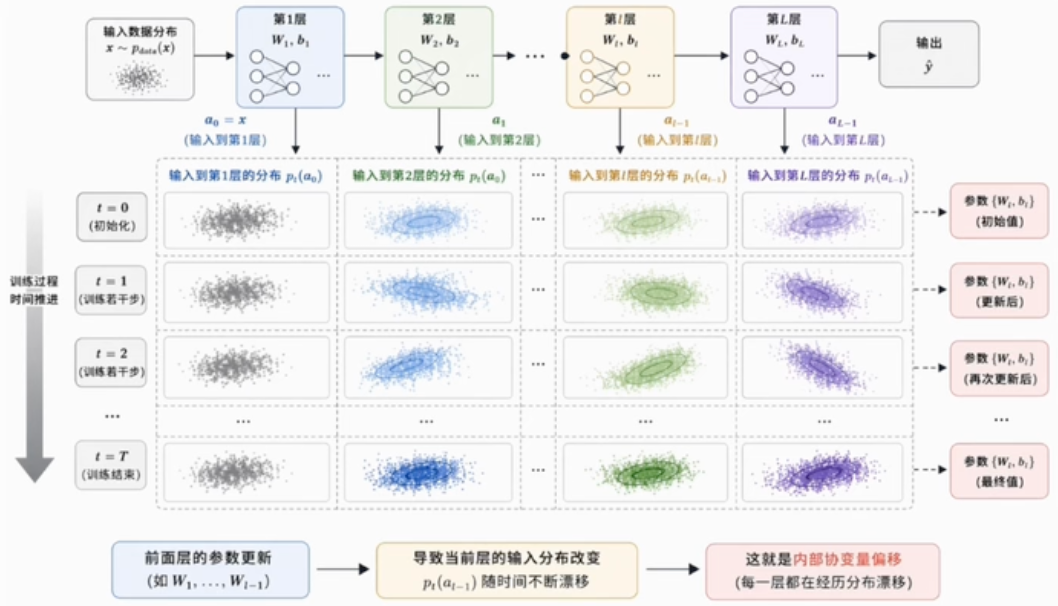
在神经网络中怎么做归一化
归一化的操作只有两步:减均值、除标准差。要在网络里使用,只需要回答一个问题——均值和标准差从哪里来。
下面先看 BatchNorm 与 LayerNorm,再补充 GroupNorm 和 RMSNorm:
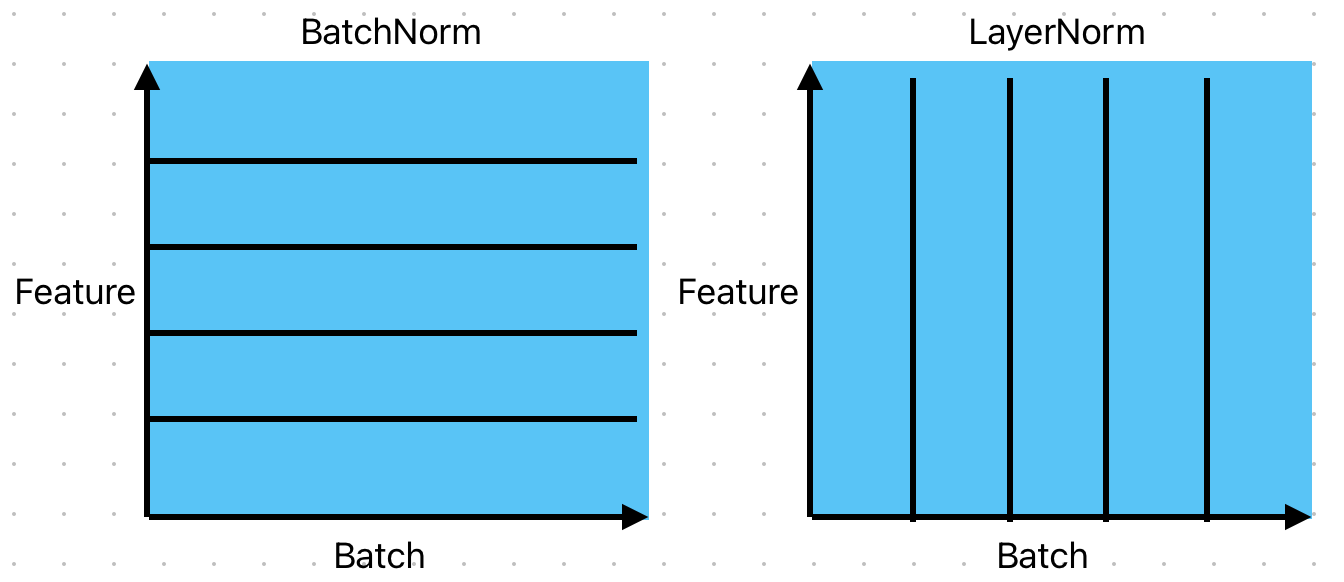
批归一化
批归一化(BatchNorm)就是在一批样本中对每个特征做归一化
nn.BatchNorm(out)使用场景:CNN、MLP、batch较大
网络结构:[784, 256, 256, 256, 256, 256, 256, 10]
6层MLP,每层Linear之后、ReLU之前各插一个BatchNorm1d:
🔍 展开查看:代码实现
import torch
import torch.nn as nn
def make_deep_mlp_bn(depth=6, width=256, in_dim=784, out_dim=10):
layers = [nn.Flatten()]
last = in_dim
for _ in range(depth):
linear = nn.Linear(last, width)
# 使用Kaiming Normal初始化权重
nn.init.kaiming_normal_(linear.weight, nonlinearity='relu')
# 将偏置项初始化为 0
nn.init.zeros_(linear.bias)
# 按照:线性层 -> 批归一化层 -> 激活函数的顺序组合
layers += [linear, nn.BatchNorm1d(width), nn.ReLU()]
last = width
# 最后一层:输出层(通常不加 BN 和 ReLU)
layers.append(nn.Linear(last, out_dim))
return nn.Sequential(*layers)
# 示例:实例化模型并打印结构
if __name__ == "__main__":
model = make_deep_mlp_bn()
print(model)层归一化
层归一化(LayerNorm)就是在同一个样本内、跨所有特征维度做归一化。
nn.LayerNorm(out)使用场景:Transformer、RNN、变长序列
其他归一化
GroupNorm:
BN与LN的折中:把通道分成若干组,每组内一起计算mean/var。既不依赖batch,也不像LN那样把所有通道混在一起。在batch size极小的CNN(目标检测等)中是BN的常见替代。
RMSNorm:
LN的进一步简化:去掉减均值这一步,只除以均方根,
LLaMA、Mistral、Qwen等当代大语言模型几乎全部采用。
- 跨 batch 中样本统计同一通道/特征的均值与方差。
- 训练和推理行为不同,推理依赖运行统计量。
- 常用于 CNN 和 batch 较稳定的 MLP。
4.4 正则化与泛化
训练中的过拟合: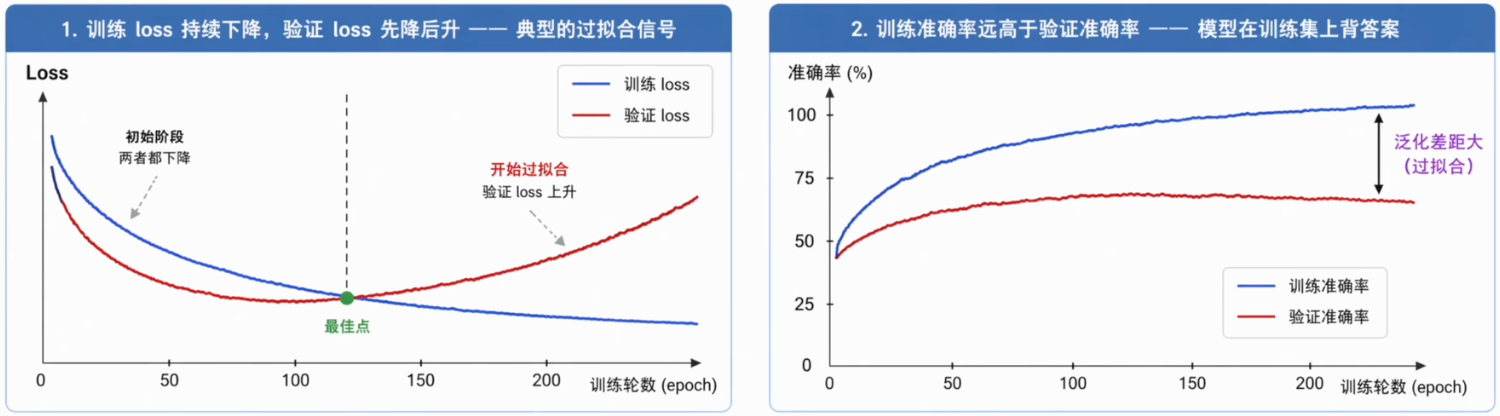
正则化:一系列对抗过拟合的技术,迫使模型学习更简洁、更通用的模式,而不是记忆训练数据的细节。
深度学习中常见的正则化技术包括:
- L1/L2:惩罚大权重。
- 权重衰减:向0衰减参数。
- Dropout:随机关闭神经元。
- Early Stop:在恶化前停训。
- 数据增强:扩大训练分布。
L1与L2正则化
经典思路:在原始损失函数中引入权重惩罚项,对过大的权重施加约束,迫使模型倾向于选择数值更小的权重。
其中 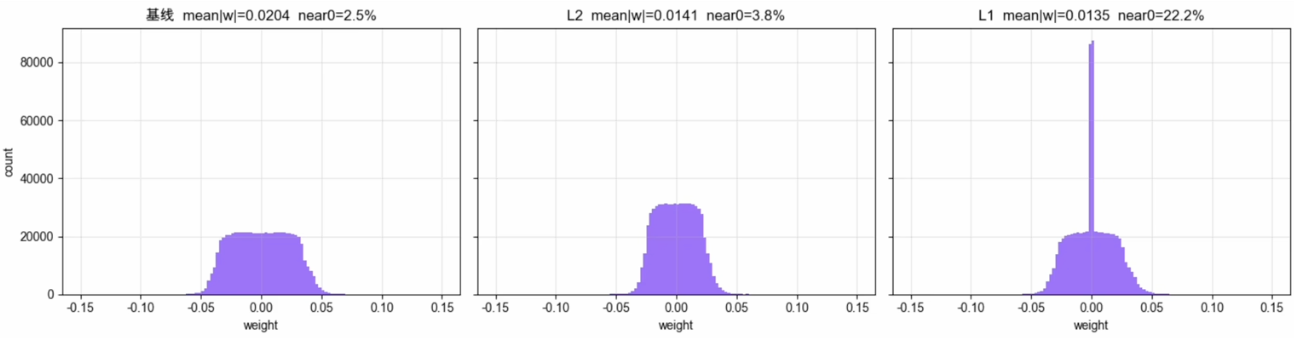
倾向于得到稀疏权重,部分参数可能被压到
💡神经网络的泛化依赖协同作用和参数的平滑分布,而非剔除特定神经元。L2处处可导,对SGD、Adam等梯度优化算法更友好。
在 PyTorch 中,可以通过优化器的 weight_decay 参数表达参数惩罚。以下无动量 SGD 示例与在损失中加入
optimizer = optim.SGD(
model.parameters(), lr=0.01, momentum=0.0, weight_decay=1e-4
)引入动量、自适应缩放、参数组或其他变换后,需要区分“把 L2 项加入梯度”和“解耦权重衰减”的实现语义。
权重衰减
权重衰减的核心思路是在每次梯度更新时,强制让权重乘以一个略小于 1 的因子,使其按比例自然缩小:
是第 步的权重 是学习率 是权重衰减系数(通常 )
💡 每个权重就像绑了一根回归原点的弹簧——梯度没有强烈要求它增大时,它就会随时间自然衰减到零附近。
🔍 展开查看:无动量标准 SGD 下 L2 与权重衰减为何等价
L2 正则化:在损失函数层面给大权重施加惩罚项
权重衰减:在优化器层面直接对参数动刀,每步乘以衰减因子
两者在概念上是两件事。但把 L2 项代回 SGD 更新公式、对
① 总损失
② 求导
③ SGD 更新
④ 提取公因式
展开后的公式与直接做权重衰减一致,因此二者在无动量的标准 SGD 下数学等价;不要把该结论无条件推广到 Adam 等自适应优化器。
⚡ 易混淆点:Adam 中的 L2 与解耦权重衰减
Adam 会根据历史梯度的平方和(二阶动量
因此,L2 惩罚项会和任务梯度一起进入一阶矩、二阶矩与按参数缩放过程,不再对应所有参数统一按比例收缩。结果不是“Adam 无法使用 L2”,而是它与解耦权重衰减具有不同的更新语义和超参数效果。
💡AdamW!!权重衰减直接作用于权重本身,与自适应缩放完全独立。
🔍 展开查看:代码实现
# 传统语义:Adam 的 weight_decay 常表现为把 L2 项加入梯度;
# 具体行为请以当前 PyTorch 版本文档为准
optimizer_l2 = torch.optim.Adam(
model.parameters(), lr=1e-3, weight_decay=1e-4)
# 需要解耦权重衰减时,显式使用 AdamW
optimizer_adamw = torch.optim.AdamW(
model.parameters(), lr=1e-3, weight_decay=1e-2)Dropout
Dropout:随机关闭神经元
Dropout在每次前向传播以一定概率随机将部分神经元的输出置0,相当于在本次训练中将其关闭。
- 强迫独立特征:神经元不能再依赖相邻特定神经元的输出,每个都必须学习独立有用的特征。
- 近似集成视角:每个 batch 采样不同的子网络;推理时使用完整网络及期望保持缩放,可近似理解为共享参数子网络的模型平均。
model = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 512), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(512, 512), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(512, 10))训练时部分神经元不工作,剩余神经元的输出期望会被压低。为了让训练时和推理时的期望保持一致,PyTorch 采用反向 Dropout (Inverted Dropout) 机制:
训练阶段:
丢弃神经元的同时,将剩余神经元的输出除以
推理阶段:
保持模型原样输出,无需做任何缩放调整,所有神经元正常工作。
model.train() # 训练模式:Dropout 生效,激活值按比例缩放并随机丢弃
# 执行训练代码...
model.eval() # 推理模式:Dropout 失效,所有神经元正常工作,无随机丢弃
# 执行验证/推理代码...⚡ 避坑指南:推理前切换为评估模式
忘记调用 model.eval() 时,Dropout 会继续随机丢弃激活,BatchNorm 也会继续使用 batch 统计量,导致推理不稳定。评估时通常同时使用 model.eval() 与 torch.no_grad()。
Dropout 率的合理值取决于网络层位置和具体任务:
经典经验值常见
早停
既然过拟合表现为验证指标在某个时刻开始恶化,那就在恶化之前停止训练——监控验证集指标,连续若干个 epoch 没有改善就终止训练,并回退到表现最好的 checkpoint。
🔍 展开查看:代码实现
best_val_loss = float('inf')
patience = 10
no_improve = 0
for epoch in range(max_epochs):
train_one_epoch(model, train_loader, optimizer)
val_loss = evaluate(model, val_loader)
if val_loss < best_val_loss:
best_val_loss = val_loss
no_improve = 0
torch.save(model.state_dict(), 'best_model.pt')
else:
no_improve += 1
if no_improve >= patience:
print(f'Early stopping at epoch {epoch}')
breakpatience:容忍多少个 epoch 没改善,通常 5 ~ 20 是合理范围。
隐式正则化:没修改损失、没动结构,但训练步数越少,权重离初始值越近,可探索的参数空间越小,等价于限制了有效复杂度。
数据增强
扩大训练分布:对训练数据施加随机变换,让模型更难记住具体样本,被迫学习更通用的特征。
前提是变换应尽量保持标签语义;例如数字识别中的垂直翻转可能改变类别,不可机械套用。
- 翻转:仅在任务语义允许时使用水平或垂直翻转。
- 裁剪:RandomCrop。
- 旋转:在合理角度范围内随机旋转,例如
。 - 颜色抖动:亮度/对比度。
💡在计算机视觉任务中效果尤其显著————同一张图换几种角度、亮度,相当于免费多了几倍训练样本。
正则化方法总结
L1 / L2 与权重衰减限制权重规模。使用自适应优化器时,通常优先考虑 AdamW 的解耦权重衰减。
💡现代训练通常组合多种正则化方法,但不是越多越好。权重衰减、Dropout、数据增强和早停之间会相互作用,应以验证集和消融实验为依据。
4.5 工业化 MNIST 训练闭环
下面将训练集进一步划分为训练集与验证集:验证集用于早停和 checkpoint 选择,官方测试集只在方案冻结后评估一次。示例组合 AdamW、Warmup + Cosine、BatchNorm、Dropout 与早停,但这些配置仍需通过消融实验验证。
⚡ 避坑指南:测试集不能参与调参
不能根据测试集准确率反复修改网络、学习率或停止时机,否则测试集就退化成验证集,最终指标会产生乐观偏差。
🔍 展开查看:代码实现
import math
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, random_split
from torchvision import datasets, transforms
# 0. 设备配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 1. 数据准备
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
full_set = datasets.MNIST('./data', train=True, download=True, transform=transform)
test_set = datasets.MNIST('./data', train=False, download=True, transform=transform)
train_size = int(0.9 * len(full_set))
val_size = len(full_set) - train_size
train_set, val_set = random_split(
full_set, [train_size, val_size], generator=torch.Generator().manual_seed(42)
)
train_loader = DataLoader(train_set, batch_size=64, shuffle=True, num_workers=4)
val_loader = DataLoader(val_set, batch_size=256, shuffle=False)
test_loader = DataLoader(test_set, batch_size=256, shuffle=False)
# 2. 网络定义 (MLP)
model = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(256, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(256, 10),
).to(device)
# 隐藏层后接 ReLU,使用 He 初始化;输出层为线性 logits,使用 Xavier
for idx in [1, 5]:
nn.init.kaiming_normal_(model[idx].weight, nonlinearity='relu')
nn.init.zeros_(model[idx].bias)
nn.init.xavier_normal_(model[9].weight)
nn.init.zeros_(model[9].bias)
# 3. 训练配置
loss_fn = nn.CrossEntropyLoss()
epochs = 30
optimizer = optim.AdamW(model.parameters(), lr=1e-3, weight_decay=1e-2)
# Warmup + Cosine Annealing 调度器
total_steps = epochs * len(train_loader)
warmup_steps = int(0.1 * total_steps)
def lr_lambda(step):
if step < warmup_steps:
return (step + 1) / warmup_steps
progress = (step - warmup_steps) / max(1, total_steps - warmup_steps)
return 0.5 * (1 + math.cos(math.pi * progress))
scheduler = optim.lr_scheduler.LambdaLR(optimizer, lr_lambda)
# 4. Early Stopping 初始化
patience = 6
best_val_loss = float('inf')
no_improve = 0
# 5. 训练与验证闭环
for epoch in range(1, epochs + 1):
model.train()
for xb, yb in train_loader:
xb, yb = xb.to(device), yb.to(device)
# 训练 4 行核心
optimizer.zero_grad()
out = model(xb)
loss = loss_fn(out, yb)
loss.backward()
optimizer.step()
scheduler.step() # 动态更新学习率
# 验证逻辑
model.eval()
val_loss, correct, total = 0.0, 0, 0
with torch.no_grad():
for xb, yb in val_loader:
xb, yb = xb.to(device), yb.to(device)
out = model(xb)
val_loss += loss_fn(out, yb).item() * yb.size(0)
correct += (out.argmax(dim=1) == yb).sum().item()
total += yb.size(0)
val_loss /= total
print(f"Epoch {epoch:2d} | val_loss={val_loss:.4f} | val_acc={correct/total:.4f}")
# Early Stopping 检查与保存
if val_loss < best_val_loss:
best_val_loss = val_loss
no_improve = 0
torch.save(model.state_dict(), 'best_model.pt')
else:
no_improve += 1
if no_improve >= patience:
print(f"Early stopping at epoch {epoch}")
break
# 6. 测试集最终评估:只在训练与调参流程结束后执行
model.load_state_dict(torch.load('best_model.pt', map_location=device))
model.eval()
test_loss, correct, total = 0.0, 0, 0
with torch.no_grad():
for xb, yb in test_loader:
xb, yb = xb.to(device), yb.to(device)
out = model(xb)
test_loss += loss_fn(out, yb).item() * yb.size(0)
correct += (out.argmax(dim=1) == yb).sum().item()
total += yb.size(0)
print(f"Final Test Loss: {test_loss/total:.4f} | Test Acc: {correct/total:.4f}")