
图像处理应用
图像去噪方法
swinIR和mambaIR都是MRI去噪方法可探索的蓝海。
后续将基于MambaIRv2探索MRI的去噪方法。
传统MRI降噪方法分类
基于深度学习的图像去噪任务
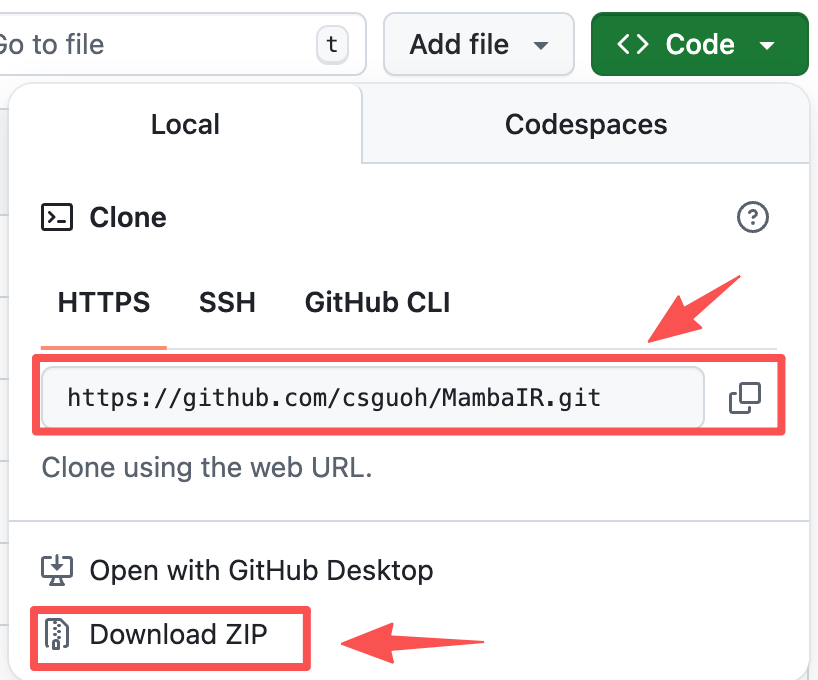
clone项目
对于一些开源项目,我们可以在作者的github上clone整个项目或者Download ZIP。
阅读readme了解模型并配置环境
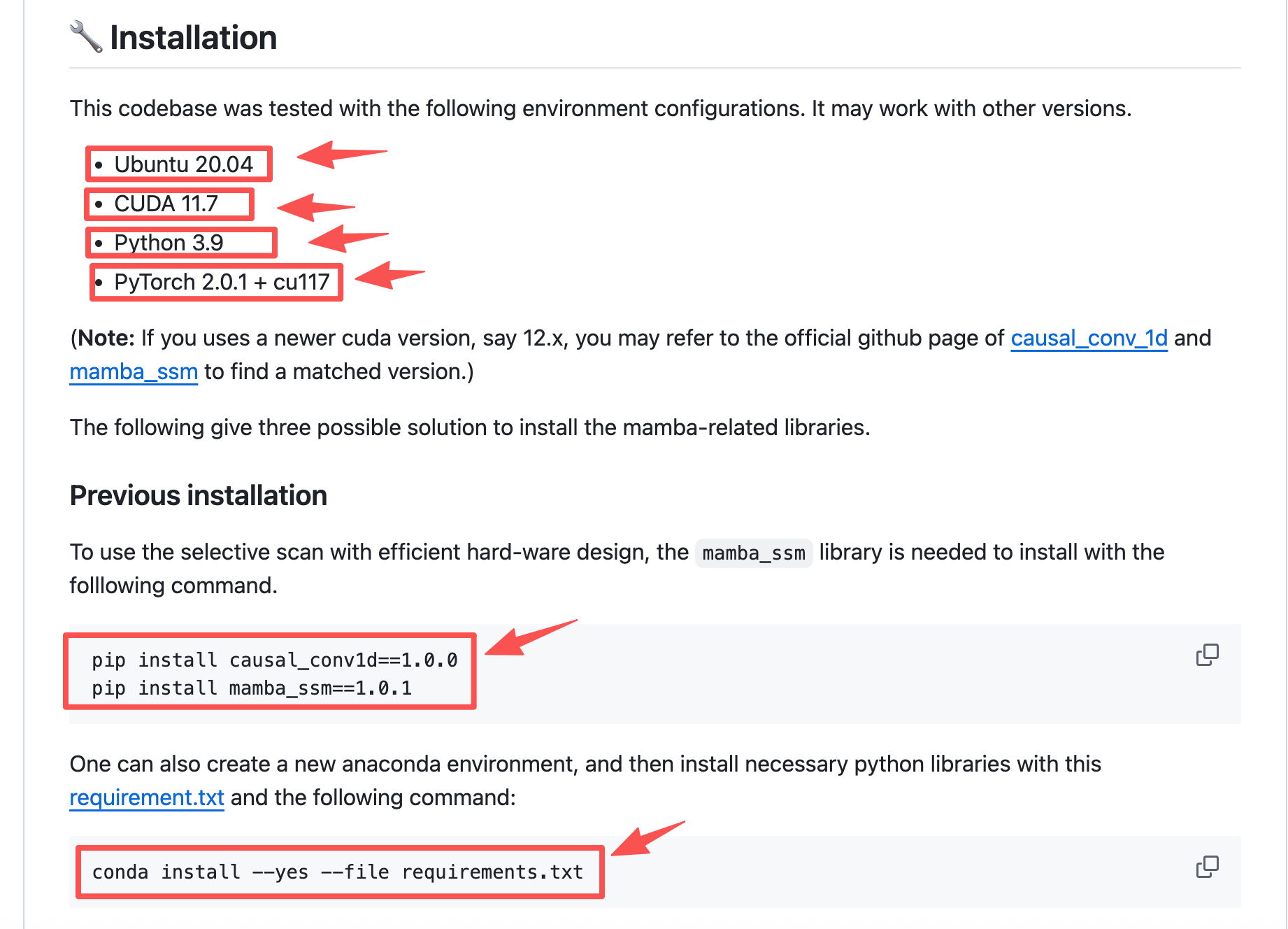
不仅是文献,项目的readme一般也会介绍模型的结构和训练成果。
尽量与项目使用同样的环境,比如:作者的MambaIR是在Linux运行的,尽量也用Linux系统,不然会出现很多BUG。
不过也不必担心,一些环境不能保持一致,可以根据弹出的error去重新配置。
我在配置时就是用windows系统,所以产生了很多问题,但最终还是通过不断地阅读资料,CSDN,DeepSeek,成功配置了环境,以下是跨系统配置环境的心得:
1.requirements.txt无法一键配置
这是必然的,因为这个文件完全是根据Linux系统生成的,所以在Windows系统下会产生一堆错误。
这时候只能重构requirements.txt,可以让DeepSeek初步重构一下requirements.txt,然后一些安装失败的就只能手动配置了。
2.官方不支持mamba_ssmwindows安装
还是只能csdn,或者博客网上去寻找解决方案。
这里提供一个causal_conv1d-1.1.1和mamba_ssm-1.1.3版本解决方案
conda create -n mamba python=3.10
conda activate mamba
conda install cudatoolkit==11.8
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
pip install setuptools==68.2.2
conda install packaging
++++++++++++++++++++++++++++++++++++++
!!!cd 到whl文件所在路径然后按以下顺序安装
pip install triton-2.0.0-cp310-cp310-win_amd64.whl
二、pip install causal_conv1d-1.1.1-cp310-cp310-win_amd64.whl
三、pip install mamba_ssm-1.1.3-cp310-cp310-win_amd64.whl夸克网盘资源:👉点我!点我!👈
图像展开方法
mamba的递推公式(自注意力方程)导致它只能处理1D序列,所以想要使用mamba来进行图像处理通常需要将图像展开为1D序列
以下是一些图像展开的方法总结
光栅扫描
光栅扫描是最简单的图像展开方法,并且为了强化数据可以分四个方向进行扫描。
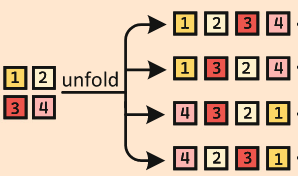
参考文献:👉MambaIR: A Simple Baseline for Image Restoration with State-Space Model👈
找到了一张更直观的图片
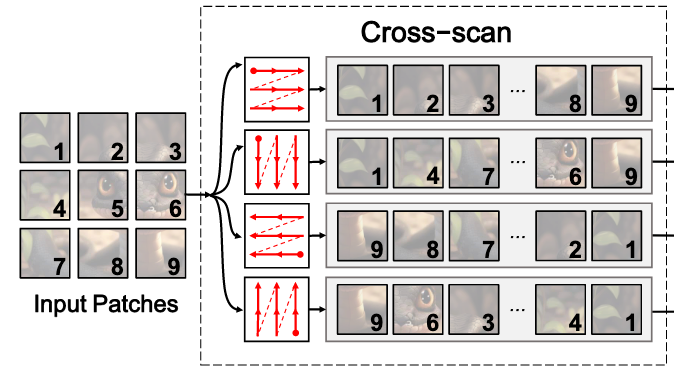
参考文献:👉VMamba: Visual State Space Model👈
希尔伯特扫描
希尔伯特曲线是一种空间填充曲线,也有文献研究使用它来展开图像,不过值得注意的一点是它要求图像的分辨率为
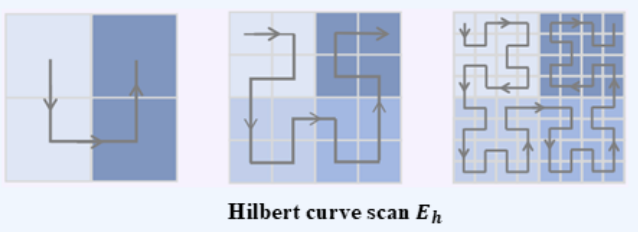
参考文献:👉SpectMamba: Integrating Frequency and State Space Models for Enhanced Medical Image Detection👈
语义引导邻域
语义引导展开,大致思路是先给每个像素分类,然后同一类的像素排在一起。
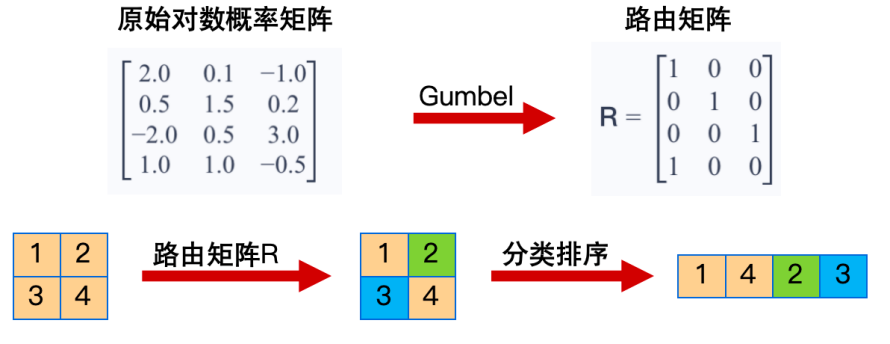
参考文献:👉MambaIRv2: Attentive State Space Restoration👈
数据增强方法
yolo中常见方法

MambaIRv2模型
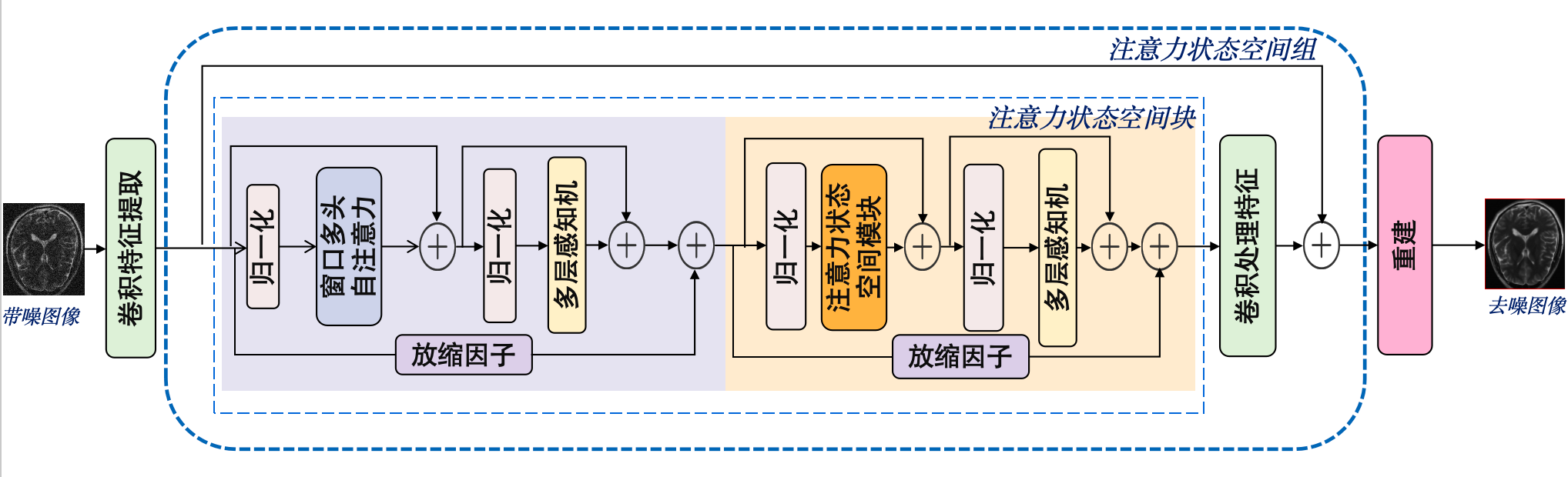
一个标准的深度网络块通常遵循“预处理 -> 空间(通道混合)混合 -> 通道混合 -> 后处理”的范式。
MambaIRv2的注意力状态空间块(ASSB)严格采用了上述的模块化设计范式,其内部结构被明确实例化为"Norm + Token Mixer + Norm + FFN"的模版
Token Mixer 是一个高度抽象的模块化概念,指的是在保持 token 数量不变的前提下,实现 token 之间信息交互与特征混合的操作单元。
Token Mixer 只是一个“接口”或“职位”,不同的底层架构会派驻不同的算子来担任这一角色:
- 在经典ViT中:Token Mixer是全局自注意力。它通过Query和Key的点积计算所有L个token之间的两两相似度,实现全局信息混合。其缺点是计算复杂度为
。 - 在SwinIR等架构中:Token Mixer是全局自注意力。它将token划分为局部窗口,只在窗口内部进行两两交互,复杂度降为
。 - 在纯CNN架构中:Token Mixer是卷积层。例如
卷积通过滑动窗口机制,将中心像素与其邻域像素的特征进行加权求和,本质上也是一种局部的Token混合。
为了同时满足局部细节恢复与全局依赖建模的需求,MambaIRv2创新地采用了层次化/渐进式的双Token Mixer设计:
Token Mixer1 --> 窗口多头自注意力(Window MHSA)
Token Mixer2 --> 注意力状态空间模块(ASSM)
Token Mixer1(局部的Token混合):
Token Mixer2(全局的Token混合):
FFN 在整体流程中扮演的是“通道混合器”的角色,它在网络已经完成了局部边缘提取(Window MHSA)和全局上下文聚合(ASSM)之后介入。
FFN --> 多层感知机(MLP)
FFN(通道混合):
与Token Mixer在不同token之间交换信息不同,FFN的操作是逐token独立的,不涉及空间维度的交互。其标准的数学表达式为:
其中
去噪任务
损失函数
常见的损失函数:
| 特性 | MSE(均方误差) | MAE(平均绝对误差) | Charbonnier 损失(MSE的近似平滑) |
|---|---|---|---|
| 公式 | |||
| 核心行为 | 二次增长 | 线性增长 | 小误差二次,大误差线性 |
| 对异常值/大误差 | 极度敏感 (惩罚重) | 鲁棒 (惩罚轻) | 鲁棒 (惩罚轻) |
| 图像细节保留 | 差 (导致模糊) | 好 (边缘锐利) | 好 (边缘锐利) |
| 收敛稳定性 | 好 (接近0时梯度小) | 一般 (梯度恒定) | 好 (接近0时平滑) |
| 可导性 | 处处可导 | 0点不可导 | 处处可导 |
| 最擅长任务 | 一般回归、高斯噪声拟合 | 含噪数据回归、图像超分 | 图像去噪、去模糊 |