
数据结构
算法是完成一项任务或解决一个问题的明确、有限的步骤和流程。
数据结构是算法高效运行的前提。
它是特意设计的数据存储和组织方式。
数据结构 = 字典排版(拼音排序、索引)
算法 = 查字典方法(二分查找)
数据结构:设计稳固的地基。
算法:规划最优的动线。
线性表、栈、队列、树、图
数组
数组是一块连续的内存空间,用于存放一组相同类型的数据。
- 连续存储:像一排紧挨着的房间。
- 固定步长:每个房间大小完全一致。
- 下表访问:通过门牌号(Index)快速定位。
int main(){
// 声明并初始化数组
int a[] = {3, 1, 4, 1, 5};
// 计算元素个数
int n = sizeof(a) / sizeof(a[0]);
// 遍历打印
for(int i = 0 ; i < n; i ++){
printf("a[%d] = %d\n", i, a[i]);
}
}逻辑视角
随机访问(Random Access):指可以直接访问任意位置的数据,而不需要从头遍历。
寻址公式:addr(i) = base + i * size。
CPU只需要进行一次乘法和一次加法,就能算出任意元素的内存地址。
数组显然符合随机访问逻辑🤓
物理视角
数组在物理内存中的连续性,完美契合了现代CPU的缓存机制。
空间局部性原理:程序倾向于访问相邻的内存位置。
预取优势(Prefetching):CPU读取a[0]时, 会顺便把a[1]...a[k]一起加载到高速缓存(Cache🚀)中。
数组的增删改查
数组在读写方面是天才,但在增删方面略显笨拙。
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
| 读取 (Access) | O(1) | 随机访问,秒级定位 |
| 修改 (Update) | O(1) | 直接覆盖内存 |
| 插入 (Insert) | O(n) | 最坏需移动 n 个元素 |
| 删除 (Delete) | O(n) | 最坏需移动 n 个元素 |
- 原则:如果你的场景是“读多写少”(如配置表、缓存索引),数组是首选。
动态数组
动态数组(Dynamic Array)
动态数组解决了静态数组“大小固定”的痛点(如Java ArrayList,C++ Vector,Python List)
自动扩容机制
初始化:申请小空间(Capacity = 10)
存满时:触发扩容(Grow)
搬家:
- 申请更大的新空间(x2)
- 将就数据复制过去
- 释放就空间
代码实现:
定义结构体:
typedef struct{
int *data; // 连续内存指针
size_t size; // 实际元素个数
size_t capacity; // 总容量
} DynamicArray;data:指向底层真正的静态数组。
size:住了多少人(Len)。
capacity:房子有多大(Cap)。
时刻保持: size
capacity
追加元素(Push Back):
void push_back(DynamicArray *da, int val){
// 1. 检查容量
if(da->size == da->capacity){
grow(da); // 扩容
}
// 2. 放入新元素
da->data[da->size] = val;
// 3. 更新计数
da->size ++;
}- 大多数情况:容量够用,直接放,O(1)。
- 极少数情况:容量满了,触发扩容,O(n)。
扩容(grow):
void grow(DynamicArray *da){
// 1. 计算新容量(通常翻倍)
int new_cap = da->capacity * 2;
int *new_data = malloc(new_cap * sizeof(int)); // 申请新空间
// 2. 搬家(复制数据)
for (int i = 0; i < da->size; ++ i){
new_data[i] = da->data[i];
}
// 3. 销毁旧房子,启用新房子
free(da->data);
da->data = new_data;
da->capacity = new_cap;
}- 申请内存:需要操作系统分配。
- 数据复制:O(n)的操作,元素越多越慢。
链表
数组的困境:数组要求大家“整齐排队”(连续内存),但如果内存里没有足够大的连续空地怎么办。
链表(Linked List)化身为一张藏宝图:
数据分散在各个角落,每个节点即有奖励(Data),又有指向下一站的线索(Pointer)。
链表是一组零散的内存块(节点),通过指针串联在一起的数据结构。
- 节点(Node):既存数据,也存线索。
- 离散存储:无需连续内存,走到哪住到哪。
- 逻辑连续:通过指针“手拉手”形成链条。
定义节点与创建链表
代码实现:
1.定义节点:
typedef struct Node{
int data; // 数据域
struct Node* next; // 指针域
} Node;
// 创建新节点
Node* createNode(int value){
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = value;
newNode->next = NULL;
return newNode;
}2.创建链表: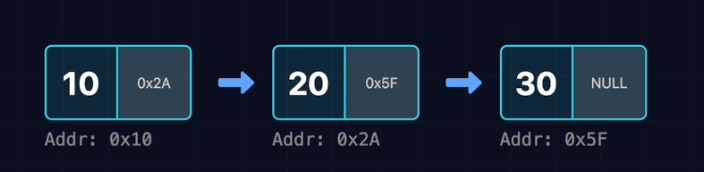
C++创建链表代码示例:
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
typedef struct Node
{
int data;
struct Node* next;
}Node;
Node* createNode(int val)
{
Node* newNode = new Node;
newNode->data = val;
newNode->next = nullptr;
return newNode;
}
int main()
{
// 创建3个节点
Node* a = createNode(10);
Node* b = createNode(20);
Node* c = createNode(30);
// 将三个节点连接
a->next = b; b->next = c;
// 打印该链表
int j = 1;
for(Node* i = a; i != nullptr; i = i->next)
{
printf("节点%d的地址为0x%x, 节点%d的值为%d, 节点%d的next为0x%x\n", j, i, j, i->data, j, i->next);
j++;
}
delete a; delete b; delete c;
return 0;
}
/*
结果:
节点1的地址为0x10, 节点1的值为10, 节点1的next为0x2A
节点2的地址为0x2A, 节点2的值为20, 节点2的next为0x5F
节点3的地址为0x5F, 节点3的值为30, 节点3的next为0x0
*/在C中创建链表,开辟空间和释放空间方式有所不同:
#include<stdlib.h>
#include<stdio.h>
typedef struct Node
{
int data;
struct Node* next;
}Node;
Node* createNode(int val)
{
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = val;
newNode->next = NULL;
return newNode;
}
int main()
{
// 创建3个节点
Node* a = createNode(10);
Node* b = createNode(20);
Node* c = createNode(30);
// 将三个节点连接
a->next = b; b->next = c;
// 打印该链表
int j = 1;
for(Node* i = a; i != NULL; i = i->next)
{
printf("节点%d的地址为0x%x, 节点%d的值为%d, 节点%d的next为0x%x\n", j, i, j, i->data, j, i->next);
j++;
}
free(a); free(b); free(c);
return 0;
}链表插入
相比数组的“搬家式”插入,链表只需要“修改指针”即可完成。
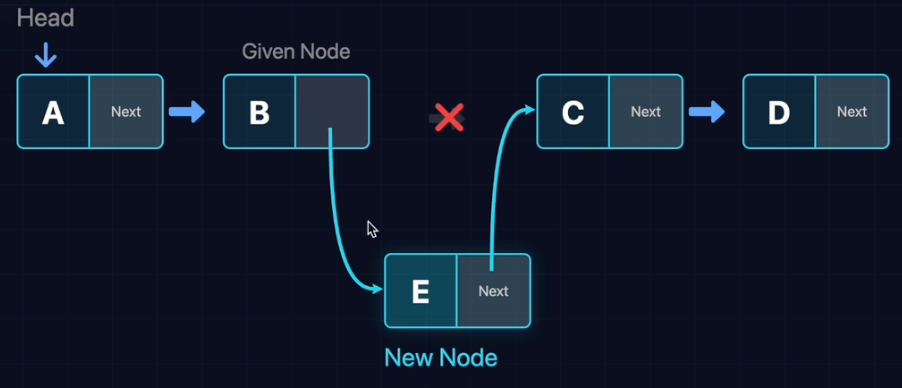
- 关键两步:1. New指向C 2. B指向New
代码实现:
A -> New -> B
void insert(Node* A, Node* New){
// 1. 先连后方(New -> B)
New->next = A->next;
// 2. 再断前缘(A -> New)
A->next = New;
}链表删除
删除节点同样只需“修改指针”,让前驱直接指向后继。
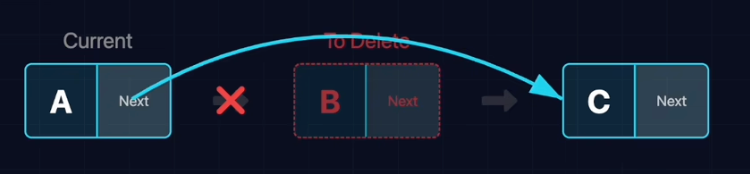
- 关键一步:A绕过B,直接指向C
删除Current的后继节点
- 定位:标记要删的节点(toDelete)
- 旁路:让当前节点指向下下个节点
- 释放:归还内存(free)
代码实现:
void deleteNextNode(Node* currentNode){
if(currentNode->next != NULL){
// 1. 找到要删除的节点
Node* toDelete = currentNode->next;
// 2. 旁路:当前指向下下个
currentNode->next = toDelete->next;
// 3. 释放内存
free(toDelete);
}
}链表读取
只知道头节点,要想找到下标为5的节点。 因为内存不连续,无法通过公式计算地址,必须从头节点开始,顺着next指针跳5次。
走法:从head出发,沿next连跳5次。

代码实现:
Node* get(Node* head, int k){
int i = 0;
while(head && i < k){
head = head->next;
i ++;
}
return head;
}链表与数组
| 特性 | 数组 (Array) | 链表 (Linked List) |
|---|---|---|
| 内存结构 | 连续,利用 CPU 缓存 | 离散,指针连接 |
| 随机访问 | ✅ O(1) 秒级定位 | ❌ O(n) 只能遍历 |
| 插入/删除 | ❌ O(n) 需要搬移数据 | ✅ O(1) 仅改指针 |
| 空间效率 | 固定大小 (或需扩容) | 动态申请 (但有指针开销) |
链表总结
链表巧妙牺牲随机访问,换取动态性与插入/删除的极致效率
链表与数组互补:数组追求“快读”,链表擅长“快插快删”。
栈
栈是一种受限的线性表,只允许再同一端(栈顶)进行插入和删除操作。
- LIFO(Last In First Out):后进者先出,如同洗盘子。
- 栈顶(Top):允许操作的一端。
- 栈底(Bottom):封死的一端,最早进来的元素在最底下。
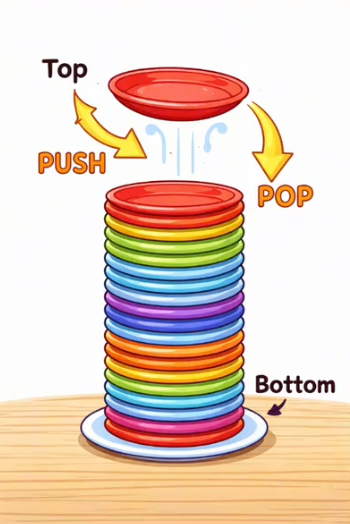
- Push(入栈)
- Pop(出栈)
栈的核心操作
无论底层用数组还是链表实现,栈对外暴露的接口是统一的,时间复杂度均为O(1)。
push(x)压栈:把元素x放到栈顶。pop()弹栈:移除并返回栈顶元素。peek()查看:只看一眼栈顶(不删除)。isEmpty()判空:检查栈里有没有元素。size()计数:返回当前元素个数。
约定:
- top指向当前栈顶元素。
- 栈空时
top = -1
代码实现:
typedef struct Stack{
int data[MAX];
int top;
} Stack;
void initStack(Stack *s){
s->top = -1;
}
bool push(Stack *s, int val){
if(s->top == MAX - 1) return false;
s->data[++ s->top] = val; // 栈顶上移并存值
return true;
}
bool pop(Stack *s, int *val){
if(isEmpty(s)) return false;
*val = s->data[s->top --]; // 弹栈并返回
return true;
}
bool peek(Stack *s, int *val){
if(isEmpty(s)) return false;
*val = s->data[s->top]; // 只读不移
return true;
}
bool isEmpty(Stack *s){
return s->top == -1;
}
int size(Stack *s){
return s->top + 1;
}括号匹配
代码实现:
// 判断左右括号是否匹配
bool isMatchingPair(char left, char right){
return (left == '(' && right == ')') ||
(left == '[' && right == ']') ||
(left == '{' && right == '}');
}
// 是否是合法括号
bool isValidBrackets(const char *str){
Stack s;
initStack(&s);
// 读取str
for(int i = 0; str[i] != '\0'; i ++){
char ch = str[i];
// 遇到左括号,入栈
if(ch == '(' || ch == '[' || ch == '{'){
push(&s, ch);
}
//遇到右括号,尝试匹配
else if(ch == ')' || ch == ']' || ch == '}'){
int topVal;
if(isEmpty(&s)) return false; // 右括号多余
pop(&s, &topVal);
if(!isMatchingPair((char)topVal, ch)){
return false; // 类型不匹配
}
}
}
// 最后栈必须为空
return isEmpty(&s);
}
int main(){
const char *str = "abc(d[e]f)[g{h}i]{jkl}";
bool calid = isValidBrackets(str);
printf("%-20s -> %s\n", str, valid ? "匹配成功" : "匹配失败");
return 0;
}后缀求值
代码实现:
int applyOperator(int a, int b, char op){
switch(op){
case '+': return a + b;
case '-': return a - b;
case '*': return a * b;
case '/': return a / b;
}
return 0;
}
int evaluatePostfix(const char *expr){
Stack s;
initStack(&s);
for(int i = 0; expr[i] != '\0'; i ++){
char c = expr[i];
if(c == ' ') continue;
// 如果是数字
if(isdigit(c)){
push(&s, c - '0');
}
// 如果是运算符
else if(isOperator(c)){
int a, b;
pop(&s, &b); // 先出栈的是右操作数
pop(&s, &a); // 后出栈的是左操作数
int result = applyOperator(a, b, c);
push(&s, result);
}
}
int finalResult;
pop(&s, &finalResult);
return finalResult;
}中缀转后缀
代码实现:
// 辅助:获取优先级(*/ > +-)
int getPriority(char op){
if(op == '*' || op == '/') return 2;
if(op == '+' || op == '-') return 1;
return 0; // '('优先级最低
}
void infixToPostfix(const char* infix, char* postfix){
Stack s;
initStack(&s);
int j = 0; // postfix写入位置
for(int i = 0; infix[i] != '\0'; i ++){
char c = infix[i];
if(c == ' ') continue;
// 1. 数字:直接输出
if(isdigit(c)){
postfix[j ++] = c;
}
// 2. 左括号:入栈待命
else if(c == '('){
push(&s, c);
}
// 3. 右括号:弹栈直到'('
else if(c == ')'){
int topVal;
pop(&s, &topVal);
while(!isEmpty(&s) && topVal != '('){
pop(&s, &topVal);
postfix[j ++] = (char)topVal;
peek(&s, &topVal);
}
pop(&s, &topVal); // 丢弃'('
}
// 4.运算符:维护优先级单调性
else{
int topVal;
while(!isEmpty(&s)){
peek(&s, &topVal);
// 栈顶 < 当前:直接入栈
if(topVal =='(' || getPriority(topVal) < getPriority(c))
break;
// 栈顶 >= 当前:弹出栈顶
pop(&s, &topVal);
postfix[j ++] = (char)topVal;
}
push(&s, c);
}
}
// 5. 收尾:弹出剩余符号
while(!isEmpty(&s)){
int topVal;
pop(&s, &topVal);
postfix[j ++] = (char)topVal;
}
postfix[j] = '\0';
}栈的应用
凡是符合“最后做的事要先被撤回/先被处理”或“先走到底,再一层层往回退”的问题,本质上都适合用栈来解决。
算法应用:
- 深度优先搜索(DFS):利用栈“先走到最深,再按相反顺序回退”,逐层展开并回溯。
- 回溯算法:保存决策路径,失败时快速撤销最近一次选择。
- 递归显式实现:手动保存函数状态,模拟系统调用栈。
系统与工程应用:
- OS函数调用栈:保证函数按”后调用、先返回“顺序执行。
- 游览器前进/后退:通过栈记录访问历史,实现逆序回退。
- 撤销操作(Undo):按相反顺序回访,优先撤销最近修改。
队列
- 入队(Enqueue):新来的只能排在队尾(Rear)。
- 出队(Dequeue):离开的永远是队头(Front)。
- 双端操作:一端只进,另一端只出。
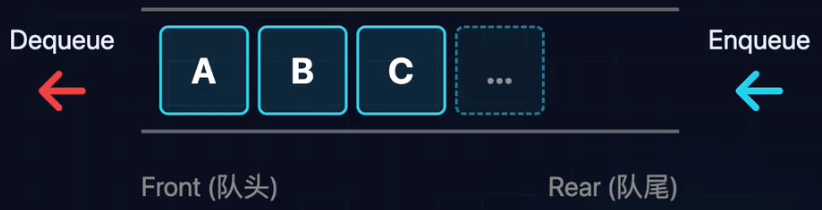
- 先进先出(FIFO,First In First Out)
队列的核心操作
队列对外暴露的接口是统一的,时间复杂度均为O(1)。
enqueue(x):将元素x加入队尾dequeue(): 移除并返回队头元素peek()查看队头元素(不删除)。isEmpty()判空:检查队列里有没有元素。size()计数:获取队列当前元素个数。
循环队列的实现
循环数组本质上是基于固定长度数组实现的。
通过取模运算,在逻辑上将数组的末尾与开头相连,形成一个环形结构,从而服用数组空间。
核心变量状态:
- Front(头指针):指向队列第一个有效元素的位置。
- Rear(尾指针):指向下一个即将插入数据的空位。
- Capacity(容量):数组的总长度。
![]()
循环队列的实现:
#define MAX_SIZE 128
typedef struct Queue{
int data[MAX_SIZE];
int front;
int rear;
} Queue;
bool enqueue(Queue, *q, int val){
// 1. 判满(留空法)
if((q->rear + 1) % MAX_SIZE == q->front){
return false;
}
// 2. 存数据
q->data[q->rear] = val;
// 3. 移动指针(回绕)
q->rear = (q->rear + 1) % MAX_SIZE;
return true;
}- 不需要size变量也能维护状态。
- Rear指向的是空位,所以先存数据,再移指针。
- 容量上限固定,适合内存敏感或负载可以预测的场景。
bool dequeue(Queue *q, int *val){
// 1. 判空
if(q->front == q->rear){
return false;
}
// 2. 取数据
*val = q->data[front];
// 3. 移动头指针(回绕)
q->front = (q->front + 1) % MAX_SIZE;
return true;
}链表队列的实现
链表实现队列
如果无法预估计数据量,或者需要频繁扩容,链表(Linked List)是更好的选择。
- 无限容量:仅受内存限制,无isFull。
- 头尾指针:
- front指向链表头节点(出队)。
- rear指向链表尾节点(入队)。

- 入队:队列为空front和rear指向新节点,否则只更新rear。
- 出队:当队列中只剩下一个元素时,手动将rear也设为NULL。
typedef struct Node{
int data;
struct Node *next;
}Node;
typedef struct LinkedQueue{
Node *front;
Node *rear;
}LinkedQueue;
void enqueue(LinkQueue *q, int val){
Node *n = malloc(sizeof(Node));
n->data = val; n->next = NULL;
// 特判空队列
if(q->rear == NULL){
q->front = q->rear = n;
}
else{
q->rear->next = n;
q->rear = n;
}
}
bool dequeue(LinkedQueue *q, int *val){
if(!q->front) return false;
Node *t = q->front;
*val = t->data;
q->front = q->front->next;
// 特判队空,重置rear
if(!q->front) q->rear = NULL;
free(t);
return true;
}链表队列的使用场景:
尽管基于循环数组的队列在追求极致吞吐量和缓存亲和性的场景下表现优异,但在并发变成、操作系统内核以及容量波动较大的复杂场景中,链表实现的队列依然拥有不可替代的地位。
1.消除扩容抖动
数组扩容会有笋尖的性能尖峰(Stop-the-World)。链表入队永远是稳定的O(1),适合实时系统。
2.并发锁粒度更小
数组队列通常需要锁住整个结构。链表队列天然头尾分离,入队和出队互不干扰,可实现细粒度锁或无锁队列(Lock-free)。
3.避免内存浪费
不需要像数组那样与分配一大块连续内存,对内存碎片容忍度高。
4.大对象传递
如果队列存的是很重的对象(如PCB),链表传递指针比数组拷贝整个数据块要快得多。
队列场景
广度优先搜索(BFS):
层序遍历的基础。比如地图导航找最近路线、社交网络找三度好友。
消息队列(MQ):
Kafka/RabbitMQ。用于削峰填谷和系统解耦。生产者发消息入队,消费者按能力出队处理。
操作系统调度:
CPU就绪队列。所有进程排队等待CPU时间片(Time Slice)。
栈vs队列
| 特性 | 栈 (Stack) | 队列 (Queue) |
|---|---|---|
| 逻辑结构 | LIFO (后进先出) | FIFO (先进先出) |
| 入口 | 栈顶 (Top) | 队尾 (Rear) |
| 出口 | 栈顶 (Top) | 队头 (Front) |
| 核心思想 | 回溯、撤销、深度优先 | 缓冲、公平、广度优先 |
哈希表
一种用键(Key)快速定位值(Value)的数据结构。

- Key:查找的标识(如学号)。
- Bucket:存储数据的容器(数组)。
- Hash Function:转换器(Key->整数)。
- 策略:用空间(数组)换时间(计算)。
哈希函数
将任意长度的输入,转换为固定长度的输出(下标)。Index = Hash(Key) % Capacity
// 简单的字符串哈希
unsigned int simpleHash(char *key, int cap){
unsigned int hash = 0;
while(*key){
hash = 31 * hash + *key; // 31是质数
key ++;
}
return hash % cap;
}- 转整数:把字符串变成数字。
- 取模:%capacity确保落在数组范围内。
- 定位:拿到合法的数组下标。
哈希冲突
鸽巢原理:如果鸽子比巢穴多,肯定有两只鸽子挤在一起。
拉链法
拉链法(Separate Chaining)
桶内不直接存数据,而是存一个链表头指针。
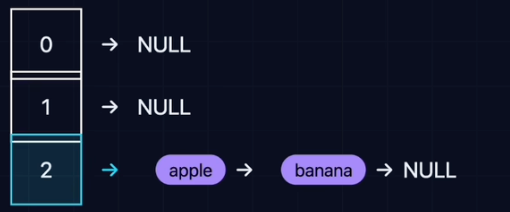
- 插入:计算下标 -> 找到链表头 -> 头插法/尾插法放入。
- 查找:计算下标 -> 遍历该位置的链表 -> 比对Key。
哈希表实现
定义结构体:
typedef struct Entry{
char *key;
int value;
struct Entry *next; // 链表指针
}Entry;
typedef struct HashTable{
// 指针数组:每个元素是链表头
Entry *buckets[TABLE_SIZE];
}HashTable;- Entry(节点):存储Key,Value和Next指针。
- HashTable:一个数组,数组存的是Entry*。
- 初始化时,要把所有buckets置为NULL。
put()函数:
void put(HashTable *table, char *key, int val){
int idx = hash(key) % TABLE_SIZE;
// 1. 遍历链表,检查Key是否已存在。
Entry *cur = table->buckets[idx];
while(cur){
if(strcmp(cur->key, key) == 0){
cur->value = val; // 更新
return ;
}
cur = cur->next;
}
// 2. 不存在,头插法插入新节点
Entry *new_node = malloc(sizeof(Entry));
new_node->key = strdup(key);
new_node->value = val;
new_node->next = table->buckets[idx]; //接旧头
table->buckets[idx] = new_node; //换新头
}- 计算
hash(key)得到数组下标i。 - 找到
table[i]对应的链表。 - 遍历链表:
- 如果发现Key已经存在,更新Value。
- 如果遍历完没找到,将新节点添加到链表中
get()函数:
int get(HashTable *table, char *key){
int idx = hash(key) % TABLE_SIZE;
Entry *cur = table->buckets[idx];
while(cur){
if(strcmp(cur->key, key) == 0){
return cur->value; // 找到了
}
cur = cur->next;
}
return -1; // 没找到
}哈希表的应用
- 缓存(Cache):Redis核心。键值对极速读写。
- 唯一性(Set):去重、判断是否存在。Set底层就是Map。
树
树:分治与递归的艺术
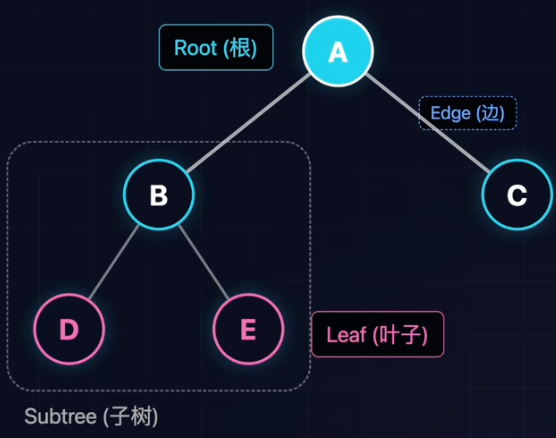
- 树是N个节点的有限集合。
- N = 0:空树。
- N > 0: 又一个特定的根(Root),其余节点分为M个互不相交的结合,每个集合又是一棵树(即子树Subtree)。
- 核心逻辑:一对多(One-to-Many)。
树的关系
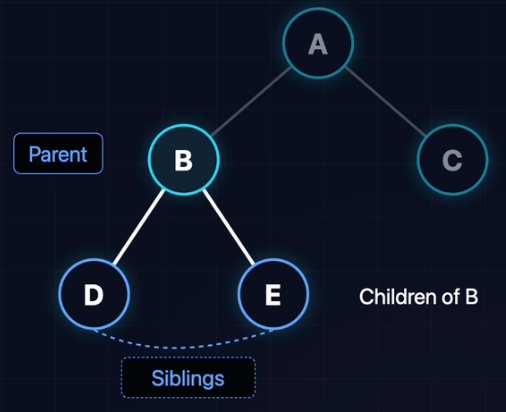
- 父(Parent):若A有子树B,则A是B的父节点。
- 子(Child):B是A的子节点。
- 兄弟(SibLing):共享同一个父节点的节点们。
- 祖先(Ancestor):从根到该节点路径上的所有节点。
- 后代(Descendant):某节点子树中的所有节点。
树的度
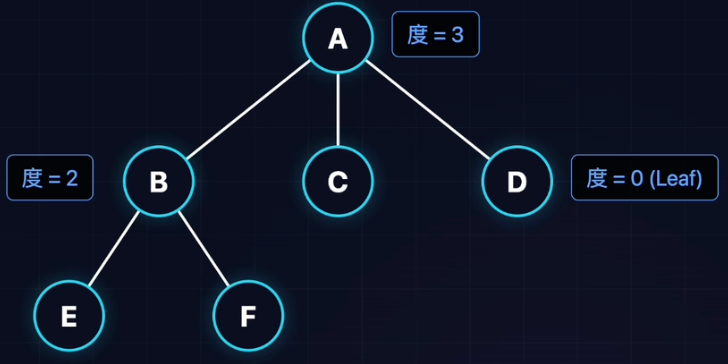
- 节点的度:一个节点拥有子树的个数(它分了几个叉)。
- 树的度:树中所有节点度的最大值。
- 二叉树(Binary Tree)的特点就是:树的度
。
树的层、高度、深度
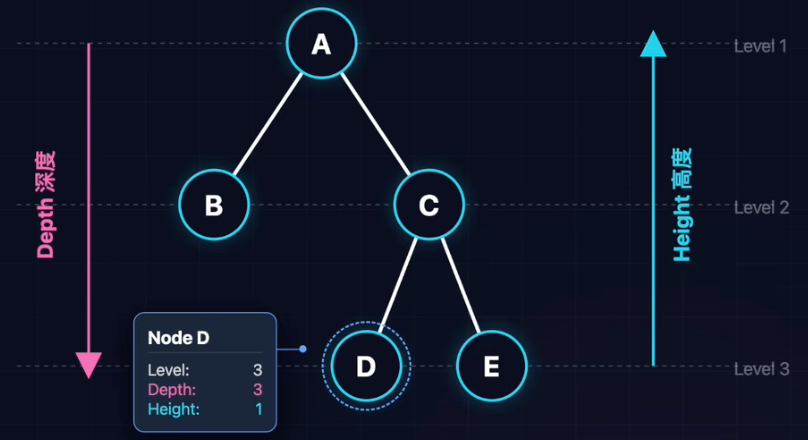
层(Level):从根开始数,Root是第1层。
深度(Depth):从上往下数。
高度(Height):从下往上数。
起始值定义差异(1 vs 0):
- 节点派(Start = 1) 国内教材/考研/LeetCode。
- 边派(Start = 0) 国外经典教材(如CLRS)。
树的形态
- 多叉树(Generic Tree): 每个节点可以有任意多个子节点。
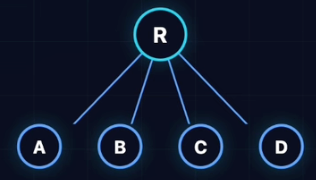
- 应用:文件系统、目、索引。
- 二叉树(Binary Tree):每个节点最多两个子节点(分左、右)。
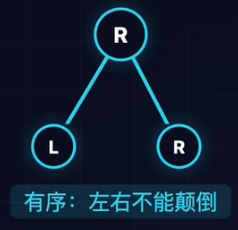
- 应用:二分查找、判断题。
二叉树的种类
- 完美二叉树(Perfect)
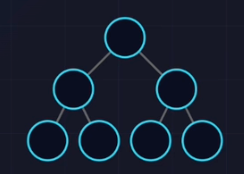
- 除了叶子,所有节点度为2。
- 所有叶子在同一层。
- 非常完美,但很少见。
- 完全二叉树(Complete)
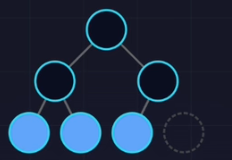
- 最后一层叶子靠左排列。
- 适合数组存储(堆Heap)。
- 完满二叉树(Full)
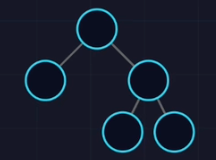
- 节点要么没孩子,要么有2个,没有独生子女(Huffman树)。
- 平衡二叉树(Balanced)
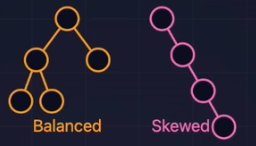
- 任意节点左右高度差
。 - 防止退化为链表,保证效率O(log n)。
树的实现
顺序存储
顺序存储(数组实现):
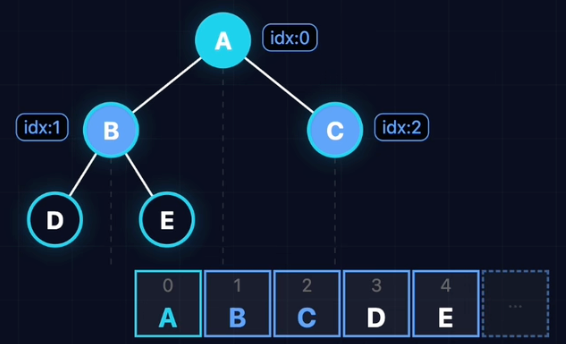
- 利用数组下标关系模拟树结构
- Left:2i + 1, Right:2i + 2
- Parent:[(i - 1) / 2]
适合:完全二叉树(如二叉堆)。
define MAX_N 100
char tree[MAX_N]; // 0 表示空节点
// 1. 初始化
void initTree(){
for(int i = 0; i < MAX_N; i ++) tree[i] = 0;
}
// 2. 设置根节点
void setRoot(char val){
tree[0] = val;
}
// 3. 设置左孩子(2i + 1)
void setLeft(int parentIdx, char val){
if(tree[parentIdx] == 0) return ; // 父不存在
int idx = 2 * parentIdx + 1;
if(idx < MAX_N) tree[idx] = val;
}
// 4. 设置右孩子(2i + 2)
void setRight(int parentIdx, char val){
if(tree[parentIdx] == 0) return ; // 父不存在
int idx = 2 * parentIdx + 2;
if(idx < MAX_N) tree[idx] = val;
}
int main(){
initTree();
setRoot('A');
setLeft(0, 'B');
setRight(0, 'C');
setLeft(1, 'D');
setLeft(1, 'E');
return 0;
}链式存储
逻辑相邻物理不一定相邻,通过指针记录“下家”在哪里。
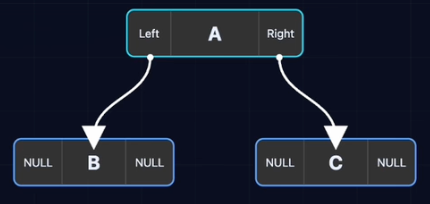
- 逻辑上是树,物理上是散落在内存各处的内存块。
#include<stdlib.h>
// 1. 定义节点结构
typedef struct TreeNode{
char val;
struct TreeNode *left;
struct TreeNode *right;
}Node;
// 2. 创建新节点
Node* createNode(char val){
Node* node = (Node*)malloc(sizeof(Node));
node->val = val;
node->left = NULL;
node->right = NULL;
return node;
}
// 3. 模拟构建过程( A -> B, C)
void buildTree(){
Node* root = createNode('A');
Node* nodeB = createNode('B');
node* nodeC = createNode('C');
root->left = nodeB;
root->right = nodeC;
}二叉树遍历
先手动构建一棵标准二叉树
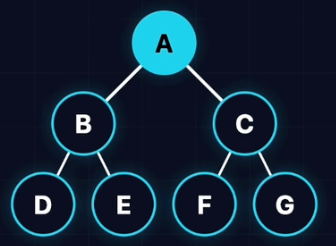
深度优先遍历
前序遍历:
根-左-右
1.访问根节点
2.遍历左子树
3.遍历右子树
”进门先办事“(如:目录复制)
void preOrder(Node* root){
// 1. 递归终止条件
if(root == NULL){
return;
}
// 2. 访问当前节点(根)
printf("%c ", root->val);
// 3. 递归遍历左子树
preOrder(root->left);
// 4. 递归遍历右子树
preOrder(root->right);
}模拟系统
中序遍历:
左-根-右
”夹在中间办“(如:BST排序)
void inOrder(Node* root){
if(!root) return ;
// 1. 先递归左子树
inOrder(root->left);
// 2. 访问当前节点(根)
printf("%c ", root->val);
// 3. 再递归右子树
inOrder(root->right);
}后序遍历:
左-右-根
”最后再收尾“(如:删除目录)
void postOrder(){
if(!root) return;
postOrder(root->left);
postOrder(root->right);
printf("%c ", root->val);
}广度优先遍历
BFS层序遍历(Queue实现)
- 上一层节点出队时,顺手把下一层的孩子(左右带入队)。
void levelOrder(Node* root){
if(!root) return ;
Node* queue[100];
int front = 0, rear = 0;
queue[rear ++] = root;
while(front < rear){
Node* curr = queue[front ++];
printf("%c ", curr->val);
if(curr->left)
queue[rear ++] = curr->left;
if(curr->right)
queue[rear ++] = curr->right;
}
}- 节点数N小于队列MAX_SIZE(数组空间用不完),就直接剩去循环数组公式
二叉搜索树
二叉搜索树(BST)
将二分查找的决策路径“固化”为一种数据结构。
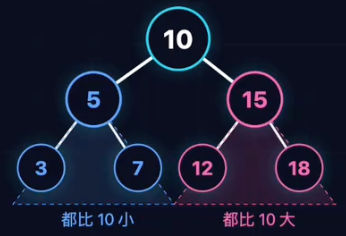
对于树中的任意节点: - 左子树所有节点的值 < 根节点 - 右子树所有节点的值 > 根节点
typedef struct TreeNode{
int val;
TreeNode *left;
TreeNode *right;
} TreeNode;
bool search(TreeNode* node, int target){
if(!node) return false;
if(target == node->val) return true;
if(target < node->val)
return search(node->left, target); // 目标在左子树
else
return search(node->right, target); // 目标在右子树
}BST递归原理
1.向下甩锅(Boss思维)
- 判断方向:
- 比我小 -> 命令左下属去办
- 比我大 -> 命令右下属去办
- 信任机制:任务派发后(递归调用),无条件信任下属能把事情办好。
2.向上汇报(指针重连)
- 汇报身份(返回值):递归返回值代表——“任务执行完后,这块地盘现在的Leader是谁”。
- 更新连接:Boss听到汇报后,必须执行“指针重连”:
root.left = insert(...)
BST插入
分情况讨论:
- 比当前节点小(插左子树)
- 比当前节点大(插右子树)
- 空树
TreeNode* insert(TreeNode* node, int val){
if(node == NULL) return createNode(val);
if(val < node->val){
node->left = insert(node->left, val);
}else if(val > node->val){
node->right = insert(node->right, val);
}
return node;
}BST删除
分情况讨论:
- 叶子节点(Leaf)直接删除。
- 只有一个孩子(父节点指向孙子)。
- 有两个孩子,找替罪羊(Successor)顶包:
- 右子树中最小的节点(或左子树最大的节点)。
- 值覆盖当前节点,然后删除那个替罪羊。
TreeNode* deleteNode(TreeNode* node, int key){
if(!node) return NULL;
if(key < node-> val)
node->left = deleteNode(node->left, key);
else if(key > node->val)
node->right = deleteNode(node->right, key);
else {
// Case 1 & 2: 0或1个孩子
if(!node->left) return node->right;
if(!node->right) return node->left;
// Case 3: 两个孩子
TreeNode* min = node->right;
while(min->left) min = min->left; // 找最小
node->val = min->val; // 值覆盖
node->right = deleteNode(node->right, min->val);
}
return node;
}BST与DFS
对BST做中序遍历得到的是一个严格升序的数组!
堆
- 结构性:完全二叉树
- 有序性:堆序性(任意节点的值
(或 )其子节点)。 - 大根堆(Max Heap):根最大(Parent
Child)。 - 小根堆(Min Heap):根最小(Parent
Child)。
- 大根堆(Max Heap):根最大(Parent
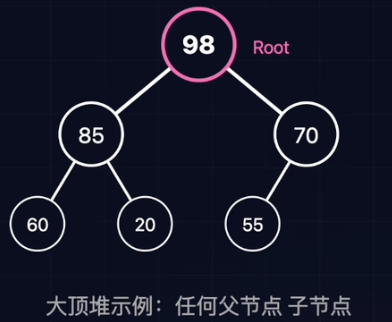
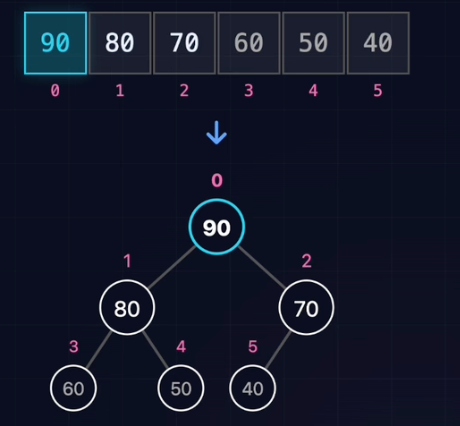
完全二叉树可以完美映射到数组,无需链表和指针。
Parent(i) = floor((i - 1) / 2)Left(i) = 2*i + 1Right(i) = 2*i + 2
堆的上浮下沉
上浮(Sift Up/Swim):小根堆中某个节点“太小了”,比父亲还小,应该往上爬,直到不再比父亲小。
实现插入操作:新元素先放在数组某尾/树的最后一个位置。
下沉(Sift Down/Sink):小根堆中某个节点“太大了”,比孩子还要大,应该往下沉,直到不比孩子大。
实现删除堆顶:把最后一个元素搬到根,根变大了,需要往下沉。
插入(Push):
公式:Append+Swim
- Append:将新元素放到数组末尾。
- Swim:执行上浮操作恢复堆序。
时间复杂度:
大根堆插入示例:
// 辅助宏定义
#define PARENT(i) ((i - 1) / 2)
// 插入操作:修改size需要传指针
void push(int *heap, int *size, int val){
// 1. 放到莫为(先赋值再 +1)
heap[(*size) ++] = val;
// 2. 上浮恢复堆序
swim(heap, *size - 1);
}
// 上浮:只是一个原子操作
void swim(int *heap, int cur){
while(cur > 0 && heap[cur] > heap[PARENT(cur)]){
swap(&heap[cur], &heap[PARENT(cur)]);
cur = PARENT(cur);
}
}
void swap(int *a, int *b){
int t = *a;
*a = *b;
*b = t;
}删除堆顶(Pop)
公式:Replace + Sink
- Remove:移除堆顶(拿到最大值)。
- Replace:用末尾元素补到堆顶。
- Sink:执行下沉操作恢复堆序。
时间复杂度:
大根堆删除堆顶(取出最大值):
// 辅助宏定义
#define LEFT(i) (2 * i + 1)
int pop(int *heap, int *size){
int ret = heap[0];
// 1. 末尾补到堆顶
heap[0] = heap[--(*size)];
// 2. 下沉恢复堆序
sink(heap, *size, 0);
return 0;
}
void sink(int *heap, int n, int i){
while(LEFT(i) < n){
int child = LEFT(i);
// 选较大的孩子
if(child + 1 < n && heap[child + 1] > heap[child]) child ++;
if(heap[i] >= heap[child]) break;
swap(&heap[i], &heap[child]);
i = child;
}
}建堆
方案A:逐个插入(Swim)
从空堆开始,依次对N个元素执行Push操作
- 新元素加在末尾,需要一路“上浮”到根。
- 大部份节点(叶子)都要经历漫长的上浮路径。
时间复杂度:
方案B:批量下沉(Sink)
原地调整:从最后一个非叶子节点开始,倒序遍历执行Sink
- 利用特性:叶子节点(占N/2)天然有序,无需操作。
- 越往上层节点越少,需要操作的节点数呈指数级减少,数学级数求和收敛于
。
时间复杂度:
批量下沉法实现大根堆建堆:
从最后一个非叶子节点开始,倒序执行下沉
- 起点:
i = n / 2 - 1 - 方向:i递减到0
- 操作:对每个i执行
sink(heap, n, i)
// 下沉操作
void sink(int *heap, int n, int i){
while(LEFT(i) < n){
int child = LEFT(i);
// 选较大的孩子
if(child + 1 < n && heap[child + 1] > heap[child]) child ++;
if(heap[i] >= heap[child]) break;
swap(&heap[i], &heap[child]);
i = child;
}
}
// 建堆
void build_heap(int *heap, int n){
// 从最后一个非叶子节点开始
for(int i = n / 2 - 1; i >= 0; i --){
sink(heap, n, i);
}
}递归建堆:
// 递归下沉操作
void heapify(int *heap, int n, int i){
int largest = i;
int left = 2 * i + 1;
int right = 2 * i + 2;
// 找出最大节点
if(left < n && heap[left] > heap[i])
largest = left;
if(right < n && heap[right] > heap[i])
largest = right;
// 如果最大不是当前节点,交换并递归
if(largest != i){
swap(&heap[i], &heap[largest]);
heapify(heap, n, largest);
}
}
// 建堆
void build_heap(int *heap, int n){
// 从最后一个非叶子节点开始
for(int i = n / 2 - 1; i >= 0; i --){
heapify(heap, n, i);
}
}堆排序
堆排序(Heap Sort)
- 建堆(Build):先将数组转化为大顶堆(
)。 - 交换(Swap):将堆顶与末尾呼唤 -> 最大值归位
- 下沉(Sink):堆大小减1,剩余部分执行下沉恢复堆序。
- 循环:重复2-3,直到堆为空。
时间复杂度:
void heap_sort(int *arr, int n){
// 1. 建堆(变成大根堆)
for(int i = n / 2 - 1; i >= 0; i --)
sink(arr, n, i);
// 2. 排序(Swap + Sink)
for(int i = n - 1; i > 0; i --){
// 把最大值(堆顶换到末尾)
swap(&arr[0], &arr[i]);
// 剩余元素(大小为i),恢复堆序
sink(arr, i, 0);
}
}数据流的中位数
问题:动态添加数字,随时返回中位数。
双堆法思路:
维护两个堆,各存一半数据:
- 大根堆(Max Heap):存较小的一半数。
- 小根堆(Min Heap):存较大的一半数。
中位数 = 两个堆顶的平均值(或元素多的那个堆顶)。
具体设计:
把数据流切成两半,保持有序:
- 左边(Max Heap):存较小的一半。
- 右边(Min heap):存较大的一半。
- 规定:左边数量
右边(最多多1个)。
如果不比较直接插入,可能会把“大数”错放到左边。
策略:新来的先去左边“过一下”,选出最大的送去右边;如果右边人多了,再匀一个回左边。
#include<stdio.h>
#include<stdlib.h>
typedef struct{
int *data;
int size;
int capacity;
int isMinHeap; // 1表示小根堆,0表示大根堆
}Heap;
// 创建堆
Heap* createHeap(int capacity, int isMinHeap){
Heap* obj = (Heap*)malloc(sizeof(Heap));
obj->data = (int*)malloc(sizeof(int) * capacity);
obj->size = 0;
obj->capacity = capacity;
obj->isMinHeap = isMinHeap;
return obj;
}
// 交换函数
void swap(int *a, int *b){
int t = *a;
*a = *b;
*b = t;
}
// 比较函数:根据堆类型判断a是否应该排在b前面
int compare(int a, int b, int isMinHeap){
if(isMinHeap) return a < b; // 小根堆:小的在前
else return a > b; // 大根堆:大的在前
}
// 上浮
void swim(Heap *obj, int k){
while(k > 0){
int parent = (k - 1) / 2;
if(compare(obj->data[k], obj->data[parent], obj->isMinHeap)){
swap(&obj->data[k], &obj->data[parent]);
k = parent;
}else {
break;
}
}
}
// 下沉
void sink(Heap *obj, int k){
while(1){
int left = 2 * k + 1;
int right = 2* k + 2;
int target = k; // 目标位置(最应该在上层的)
if(left < obj->size && compare(obj->data[left], obj[target], obj->isMinHeap))
target = left;
if(right < obj->size && compare(obj->data[right], obj->data[target], obj->isMinHeap))
target = right;
if(target != k){
swap(&obj->data[k], &obj->data[target]);
k = target;
}else {
break;
}
}
}
// 入堆(Push)
void heapPush(Heap *obj, int val){
obj->data[obj->size] = val;
swim(obj, obj->size); // 上浮新加入的元素
obj->size ++;
}
// 出堆(Pop)
int heapPop(Heap * obj){
if(obj->size == 0) return -1;
int top = obj->data[0];
swap(&obj->data[0], &obj->data[obj->size - 1]); // 交换堆顶和最后一个元素
obj->size --;
sink(obj, 0); // 下沉新的堆顶
return top;
}
// 获取堆顶
int heapPeek(Heap *obj){
if(obj->size == 0) return -1;
return obj->data[0];
}
// 释放堆内存
void freeHeap(Heap *obj){
if(obj){
free(obj->data);
free(obj);
}
}
// MedianFinder的定义
typedef struct {
Heap *minHeap; // 存较大的一半
Heap *maxHeap; // 存较小的一半
}MedianFinder;
// 初始化
MedianFinder* medianFinderCreate(){
MedianFinder* obj = (MedianFinder*)malloc(sizeof(MedianFinder));
// 题目最多调用50000次,每个堆分配30000足够
int capacity = 30000;
obj->minHeap = createHeap(capacity, 1); // 1:MinHeap
obj->maxHeap = createHeap(capacity, 0); // 0:MaxHeap
return obj;
}
// 添加数字
void medianFinderAddNum(MedianFinder* obj, int num){
// 1. 先放大根堆(左边)
heapPush(obj->maxHeap, num);
// 2. 将大根堆中最大的移到小根堆(右边),保证右边的数永远大于左边
int maxTop = heapPop(obj->maxHeap);
heapPush(obj->minHeap, maxTop);
// 3. 平衡大小:保证maxHeap的数量 >= minHeap的数量
// 如果minHeap太多了,就把嘴笑的拿回maxHeap
if(obj->minHeap->size > obj->maxHeap->size){
int minTop = heapPop(obj->minHeap);
heapPush(obj->maxHeap, minTop);
}
}
// 查找中位数
double medianFinderFindMedian(MedianFinder* obj){
// 如果大根堆元素多,说明总数是奇数,中位数在大根堆堆顶
if(obj->maxHeap->size > obj->minHeap->size){
return (double)heapPeek(obj->maxHeap);
}
//否则说明总数是偶数,取平均
return (heapPeek(obj->maxHeap) + heapPeek(obj->minHeap)) / 2.0;
}
// 销毁对象
void medianFinderFree(MedianFinder *obj){
if(obj){
freeHeap(obj->minHeap);
freeHeap(obj->maxHeap);
free(obj);
}
}
int main(){
MedianFinder *obj = medianFinderCreate();
printf("添加 10 :");
medianFinderAddNum(obj, 10);
printf("中位数 = %.2f\n", medianFinderFindMedian(obj));
printf("添加 27 :");
medianFinderAddNum(obj, 27);
printf("中位数 = %.2f\n", medianFinderFindMedian(obj));
printf("添加 13 :");
medianFinderAddNum(obj, 13);
printf("中位数 = %.2f\n", medianFinderFindMedian(obj));
printf("添加 49 :");
medianFinderAddNum(obj, 49);
printf("中位数 = %.2f\n", medianFinderFindMedian(obj));
printf("添加 35 :");
medianFinderAddNum(obj, 35);
printf("中位数 = %.2f\n", medianFinderFindMedian(obj));
medianFinderFree(obj);
return 0;
}堆的场景
优先队列:普通队列是FIFO,优先队列是BIFO。
- 谁优先级高,谁先出队。
- 插入
,取出 。
Top-K问题:从N个元素中找到前K大/小的元素
- 排序法:
。 - 堆解法:
(维护大小为K的堆)。
- 排序法:
图算法加速:在图论算法中,利用堆快速获取“当前距离最近”的节点。
- Dijkstra:寻找最短路径。
- 性能提升:将查找最小值从
优化到 。
堆vsBST
| 维度 | 堆 (Heap) | 二叉搜索树 (BST) |
|---|---|---|
| 主要目标 | 快速找极值 (Top 1) | 快速找任意值、排序 |
| 查找 Max/Min | O(1) | O(log N) (或者 O(H)) |
| 查找任意值 | O(N) (无序,只能遍历) | O(log N) |
| 有序性 | 弱序 (仅父子有序) | 强序 (左 < 根 < 右) |
| 应用场景 | 优先队列、Top K、中位数 | Set/Map 实现、数据库索引 |
哈夫曼树
哈夫曼树引入场景:发送电报
假设我们要发送一段文字:“BAD CAD FEED”
传统方法:定长编码
- 每个字符用固定长度的二进制表示,如
A:000, B:001, C:010...
变长编码思路:
- 高频字符 -> 短编码(如'e' -> 10)
- 低频字符 -> 长编码(如'z' -> 110011)
为了实现变长编码,通常借助二叉树结构:
- 编码长度 -> 节点深度(路径长度)
- 字符频率 -> 节点权重
- 目标:总长度(
)最小。
核心指标:带权路径长度(Weighted Path Length,WPL)
哈夫曼树定义:WPL最小的二叉树
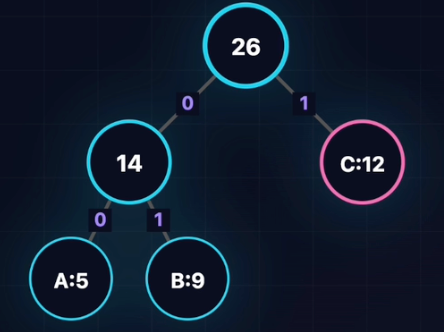
- 核心思想:权值大的靠上,权值小的靠下
- 这样可以保证高频字符编码短,总长度最小。
生成规则:
- 左分支标0、右分支标1
- 路径即编码:从根到叶子路径上的01序列
前缀特性(Prefix Property):
- 任何一个字符的编码都不是另一个字符编码的前缀。
- 例如:如果A是0,那么B绝不可能是01.因为字符都在叶子节点,不会出现在路径中间。保证了解码的唯一性,无需分隔符。
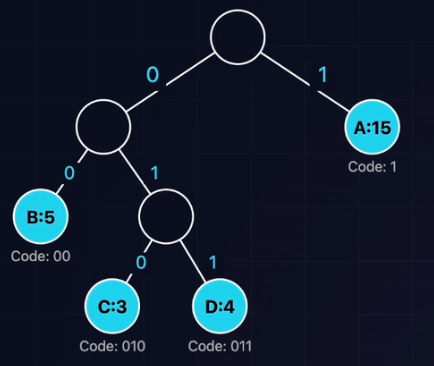
哈夫曼树构造:贪心策略
- 构成森林:将每个字符看作一棵单节点树。
- 选两最小:从森林中选出根权值最小两棵树。
- 合并新树:
- 创造新父节点,权值为两子之和。
- 两棵小树作为左右子树。
- 删旧添新:从森林中删除选中的两棵树,加入新树。
- 重复:直到森林只剩一棵树。
typedef struct TreeNode{
int weight;
char val; // 仅叶子节点有效
struct TreeNode *left, *right;
}TreeNode;
// 优先队列节点(存指针)(直接用STL中的优先队列)
PriorityQueue<TreeNode*> minHeap;
TreeNode* buildHuffmanTree(int *weights, char *chars, int n){
// 1. 将所有字符作为节点放入小根堆
PriorityQueue pq = createMinHeap();
for(int i = 0; i < n; i ++)
push(pq, newNode(weights[i], chars[i]));
// 2. 循环合并
while(size(pq) > 1) {
// 取出最小的两个
TreeNode* left = pop(pq);
TreeNode* right = pop(pq);
// 合并
TreeNode* parent = newNode(left->weight + right->weight, 0);
parent->left = left;
parent->right = right;
// 放回
push(pq,parent);
}
return pop(pq); // 返回根节点
}哈夫曼树不是:”滚雪球“,而是“森林进化”:
- 新生成的子树(节点)权值可能很大。
- 贪心策略要求:每一刻都必须选全局最小的两个,无论它是原来的叶子,还是新生成的子树。
字典树
字典树(Retrieve)
核心定义:
- 多叉树结构:每个节点代表一个字符。
- 公共前缀:同前缀单词共享路径。
- 根节点:空节点,不包含字符。
- 路径:根到节点的路径字符=字符串
空间换时间
- 利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较。
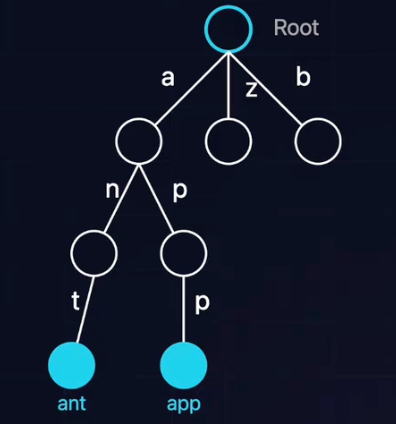
结构体定义要素:
- Next指针数组:指向子节点(如果是全小写字母,大小为26)。
- 结束标记(isEnd):布尔值(标记当前节点是否为一个单词的结尾)。
#define ALPHABET_SIZE 26
typedef struct TrieNode{
// 指向子节点的指针数组
// index 0->'a', 1->'b'...
struct TrieNode *children[ALPHABET_SIZE];
// 标记是否是单词结尾
// true 表示从根到此的路径构成了一个完整单词
bool isEndOfWord;
} TrieNode;流程:
例如:依次插入“cat”和“car”
- 从根节点触发,遍历单词字符。
- 若子节点存在:移动到下一层。
- 若不存在:新建节点,链接上去。
- 单词结束时,标记
isEnd = true
TrieNode* getNode() {
// 1. 分配内存(使用 calloc 可以同时清零)
TrieNode* newNode = (TrieNode*)calloc(1, sizeof(TrieNode));
// 2. 显式初始化(如果使用 malloc 则需要这一步)
// 由于使用了 calloc,这一步其实可以省略,因为 calloc 已经把内存置为 0
// 但为了代码清晰,通常保留逻辑或直接使用 calloc
/*
for (int i = 0; i < ALPHABET_SIZE; i++) {
newNode->children[i] = NULL;
}
newNode->isEndOfWord = false;
*/
return newNode;
}
void insert(TrieNode *root, const char *key){
TrieNode *pCrawl = root;
for(int i = 0; key[i] != '\0'; i ++){
// 计算下标:'a'->0, 'b'->1 ...
int index = key[i] - 'a';
// 如果路径不存在,创建新节点
if(!pCrawl->children[index])
pCrawl->children[index] = getNode();
// 移动指针到下一层
pCrawl = pCrawl->children[index];
}
// 标记单词结束
pCrawl->isEndOfWord = true;
}- 查单词(Whole Word):必须路径存在且
isEnd == true。 - 查前缀(StartsWith):只要路径存在即可。
bool search(TrieNode *root, const char *key){
TrieNode *pCrawl = root;
for(int i = 0; key[i] != '\0'; i ++){
int index = key[i] - 'a';
// 路径断了 -> 不存在
if(!pCrawl->children[index])
return false;
pCrawl = pCrawl->children[index];
}
// 必须同时满足:路径走通且标记了结束
return (pCrawl != NULL && pCrwal->isEnd);
}实战:LeetCode 820:单词的压缩编码
目标:构造最短字符串S,包含所有单词(以#结尾)。
规则:如果A是B的后缀,A可以“藏”在B里,不用单独写。
例如["time", "me", "bell"]
1."me"是"time"后缀 -> 合并为"time#"
2."bell"无后缀关系 -> 单独"bell#"
最终长度:len("time#") + len("bell#") = 10
思路:Trie擅长处理前缀,反转单词,让"em"变成"emit"的前缀。
构造Trie,然后遍历Trie,答案为每个最长单词+1的和。
解题步骤:
1.单词全反转:"emit","em","lleb"
2.构建Trie树:
3.关键:如果一个词是另一个词的前缀,则它不需要独立编码(被包含)
4.结构:所有叶子节点对应单词长度+1
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdbool.h>
#define ALPHABET_SIZE 26
typedef struct TrieNode {
struct TrieNode *children[ALPHABET_SIZE];
bool isEndOfWord;
} TrieNode;
// 创建新节点(使用 calloc 自动初始化)
TrieNode* getNode() {
return (TrieNode*)calloc(1, sizeof(TrieNode));
}
// 反转字符串函数
void reverseStr(char *str) {
int len = strlen(str);
for (int i = 0; i < len / 2; i++) {
char temp = str[i];
str[i] = str[len - 1 - i];
str[len - 1 - i] = temp;
}
}
// 插入单词(已反转)
void insert(TrieNode *root, const char *key) {
TrieNode *pCrawl = root;
for (int i = 0; key[i] != '\0'; i++) {
int index = key[i] - 'a';
if (!pCrawl->children[index])
pCrawl->children[index] = getNode();
pCrawl = pCrawl->children[index];
}
pCrawl->isEndOfWord = true;
}
// 深度优先遍历,统计叶子节点路径长度
void dfs(TrieNode* node, int depth, int* ans) {
bool isLeaf = true;
for (int i = 0; i < ALPHABET_SIZE; i++) {
if (node->children[i]) {
isLeaf = false;
dfs(node->children[i], depth + 1, ans);
}
}
// 是叶子节点 -> 累加长度(depth + 1个#号)
if (isLeaf && depth > 0) {
*ans += (depth + 1); // 修正此处语法
}
}
// 计算最小长度编码
int mininumLengthEncoding(char** words, int size) {
TrieNode* root = getNode();
for (int i = 0; i < size; i++) {
reverseStr(words[i]); // 反转单词
insert(root, words[i]);
}
int ans = 0;
dfs(root, 0, &ans);
return ans;
}
// 释放 Trie 树内存
void freeTrie(TrieNode* node) {
if (!node) return;
for (int i = 0; i < ALPHABET_SIZE; i++) {
if (node->children[i]) {
freeTrie(node->children[i]);
}
}
free(node);
}
int main() {
// 示例单词列表
char* words[] = {"time", "me", "bell"};
int size = sizeof(words) / sizeof(words[0]);
// 计算最小编码长度
int result = mininumLengthEncoding(words, size);
printf("Minimum Length Encoding: %d\n", result); // 应输出 10 ("time#bell#")
return 0;
}字典树vs哈希表
| 维度 | 字典树 (Trie) | 哈希表 (Hash Table) |
|---|---|---|
| 时间复杂度 | O(L)L=单词长度,与字典大小无关 | O(1) |
| 前缀查询 | 支持 (非常快) | 不支持 (只能全匹配) |
| 空间复杂度 | 较高 (大量空指针)O(ALPHABET × N × L) | 一般 (取决于 Load Factor) |
| 有序性 | 按字典序排列 | 无序 |
AVL树
AVL树:平衡的二叉搜索树,解决BST退化问题。
理想的BST(Balanced):
- 插入顺序:50,20,80,10,30(随机)
- 结构:像一棵茂盛的树,左右均匀。
- 高度:O(logN)
- 查找效率:快(只找几层)
极端的BST(Skewed):
- 插入顺序:10,20,30,40,50(有序)
- 结构:退化成链表。
- 高度:O(N)
- 查找效率:慢(退回到线性扫描)。
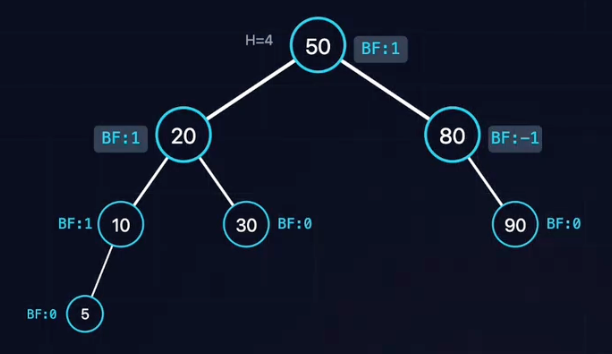
AVL树(Adelson-Velsky and Landis Tree)是最早发明的自平衡二叉搜索树,树中任意一个节点的左子树和右子树的高度差的绝对值$\le$1。
平衡因子:BFBF = Height(L) - Height(R)
铁律:任意节点的
一旦某节点
插入操作:后序处理
- 标准插入:像普通BST一样找到空位插入。
- 回溯(BackTracking):递归函数返回,沿着路径向上走。
- 更新高度:
- 计算BF:
- 检查失衡:
- BF > 1(左重):看左孩子BF。
- 左孩子
:LL(右旋)。 - 左孩子 < 0:LR(先左旋后右旋)。
- 左孩子
- BF < -1(右重):看右孩子BF。
- 右孩子
:RR(左旋)。 - 右孩子 > 0:RL(先右旋后左旋)。
- 右孩子
- BF > 1(左重):看左孩子BF。
红黑树
AVL树vs红黑树
AVL树:
- 规则:左右高度差
。 - 优点:查找极致快O(logN)。
- 痛点:插入/删除时,为了维持这种“绝对平衡”,需要频繁旋转。
红黑树(RB Tree):
- 规则:引入颜色位,通过5条性质约束。
- 效果:没有AVL那么平,但最长路径
最短路径。 - 收益:插入/删除时,旋转次数更少(常数级),大量使用变色(开销小)。
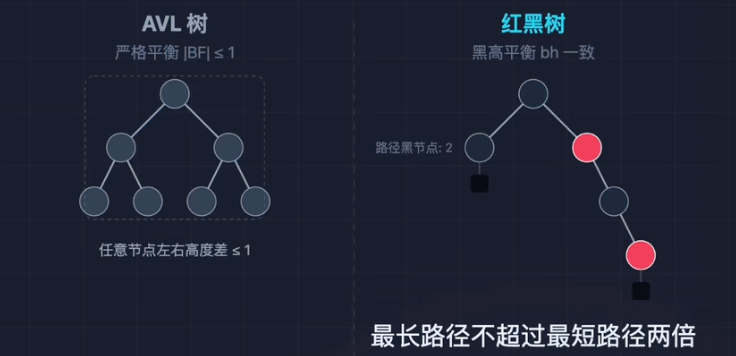
红黑树的5条铁律:
颜色属性:每个节点要么是红色,要么是黑色。
根属性:根节点必须是黑色。
叶子属性:所有叶子节点(NIL)都是黑色。
红属性(关键):不能有两个连续的红色节点。
黑高属性(关键):从任一节点到其所有后代叶子的路径上,包含相同数量的黑色节点。
口诀:根叶黑,不红红,黑路同。
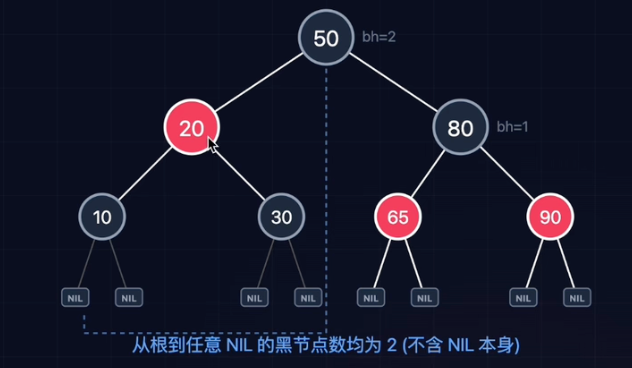
插入操作:默认为红
插入为黑色:
- 后果:所在路径黑高+1
- 问题:必然破坏“黑高属性”。
- 修复难度:全局性破坏,很难修。
插入为红色:
- 后果:如果父节点是黑,完美!无需修复。
- 风险:如果父节点是红,破坏“红红不相邻”。
- 优势:局部性破坏,好修。
修复三板斧
目标:消除双红,且不引入新的违规。
变色(Recolor):红变黑,黑变红。代价最小。
旋转(Rotate):调整结构(同AVL)。
看“叔叔”的脸色行事:
- 叔叔是红色 -> 变色。
- 叔叔是黑色 -> 旋转。
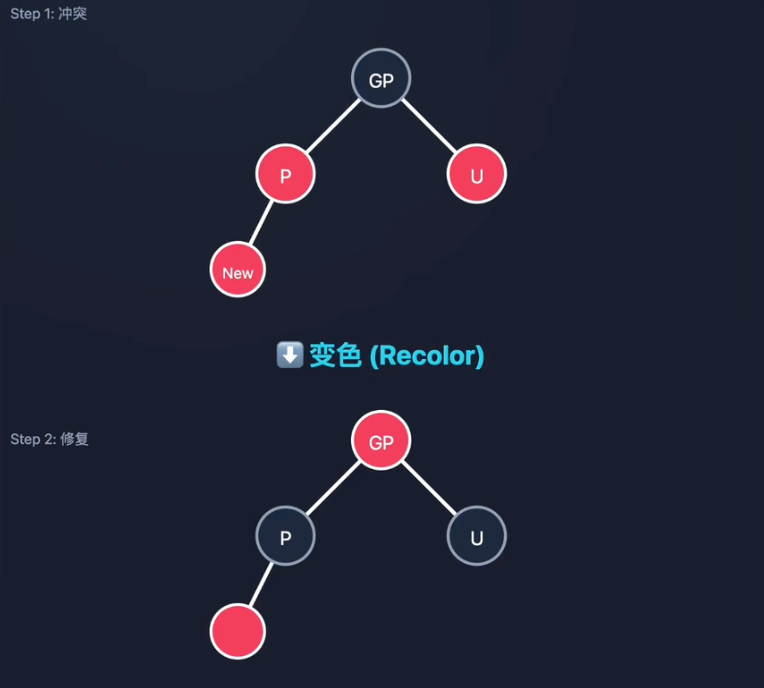
策略1:叔叔是红色 -> 变色
- 父亲(P)变黑:消除与新节点(New)的双红冲突。
- 叔叔(U)变黑:为了保持黑高平衡,叔叔也必须增加一个黑色。
- 爷爷(GP)变红:因为左右子树都各加了一个黑,所以根必须减一个黑(变红),维持整体黑高不变。
- 注意:爷爷变红后,可能会与其父节点产生新的双红冲突,需要向上递归处理。
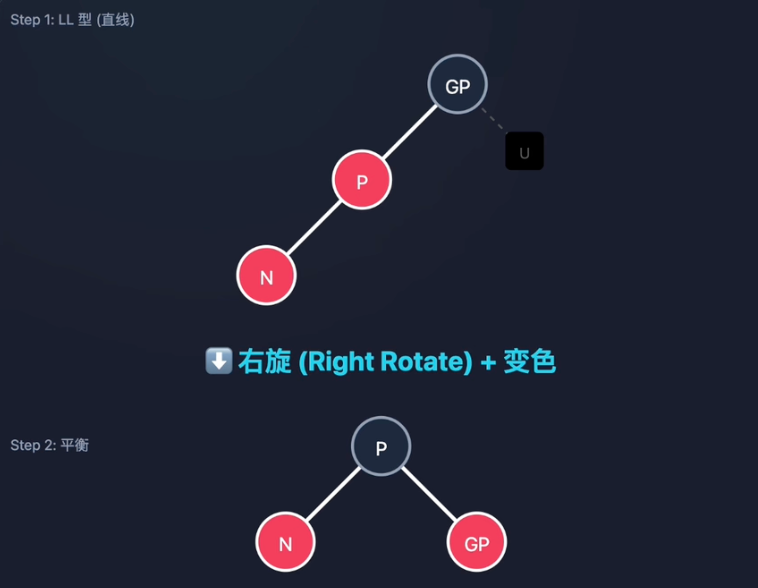
策略2:叔叔是黑(LL型) -> 右旋
- 特征:三点一线(Left-Left),叔叔是黑色或NIL。
- 变色:父亲(P)变黑,爷爷(GP)变红。
- 旋转:以父亲(P)为轴,对爷爷(GP)进行右旋。
- 结构:父节点P上位称为子树根节点,完美平衡,无需继续递归。
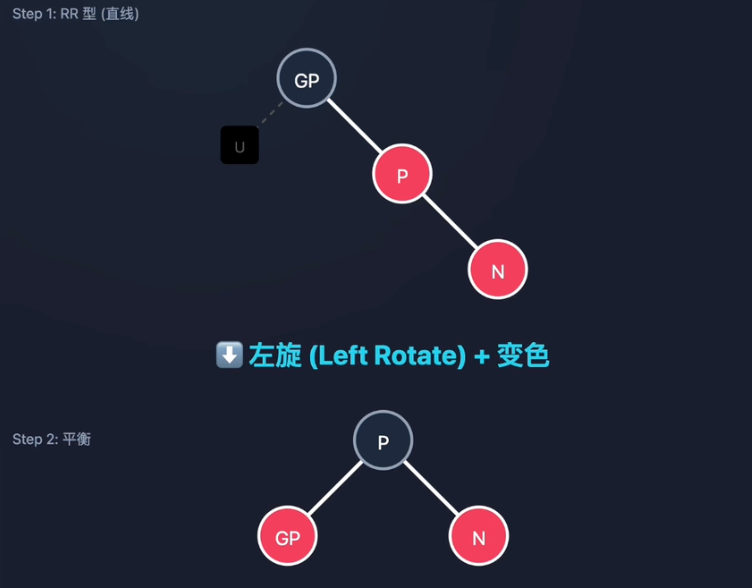
策略3:叔叔是黑(RR型) -> 左旋
- 特征:三点一线(Right-Right),与LL镜像对称。
- 变色:父亲(P)变黑,爷爷(GP)变红。
- 旋转:以父亲(P)为轴,对爷爷(GP)进行左旋。
- 结果:父节点P上位,完美平衡,同样无需递归。
插入修复操作速查表
| 场景 | 叔叔颜色 | 结构特征 | 核心操作 | 后续 |
|---|---|---|---|---|
| Case 1 | 红色 | 任意 | P, U → 黑 GP → 红 | 递归 (查 GP) |
| Case 2 (LL) | 黑色 | GP-P-N (左直线) | 右旋 GP + 变色 | 结束 |
| Case 3 (RR) | 黑色 | GP-P-N (右直线) | 左旋 GP + 变色 | 结束 |
| Case 4 (LR) | 黑色 | 左-右 (折线) | 左旋 P → 变成 LL | 转 Case 2 |
| Case 5 (RL) | 黑色 | 右-左 (折线) | 右旋 P → 变成 RR | 转 Case 3 |
- 口诀:叔红变色看祖父,叔黑直旋折变直。
AVL树vs红黑树
| 维度 | AVL 树 | 红黑树 |
|---|---|---|
| 平衡程度 | 严格 ( | 宽松 (2倍路径) |
| 查找性能 | 略快 ( | 快 ( |
| 插入/删除 | 较慢 (旋转多) | 较快 (旋转少) |
| 适用场景 | 读多写少 | 通用 / 写频繁 |
B树
B+树
图
图的应用:
- 社交网络:利用连通性做推荐,用BFS算六度分隔。
- 地图导航:将路口建模为定点,用Dijkstra算最短路径。
- 任务调度:解析依赖关系,用拓扑排序决定执行顺序。
- 互联网(Web):网页是顶点,链接是边,用PageRank算权重。
- 知识图谱:实体间建立语义关联,支持复杂推理。
- 网络拓扑:用最小生成树优化布线成本或路由广播。
图的定义:图是由顶点(Vertex)的有穷非空集合和顶点之间的边(Edge)集合组成的数据结构。G = (V, E)
- 表示“多对多(Many-to-Many)的关系。
图论基础
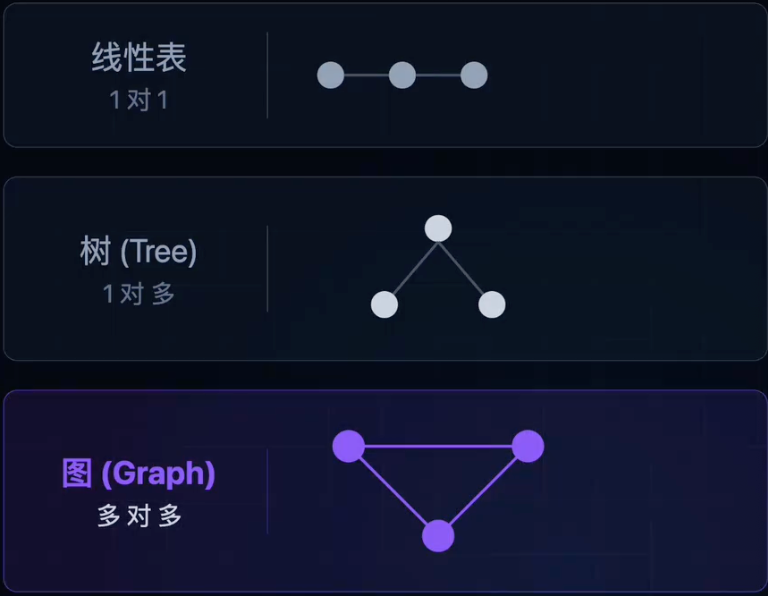
顶点、边、度、权重、方向
无向图vs有向图
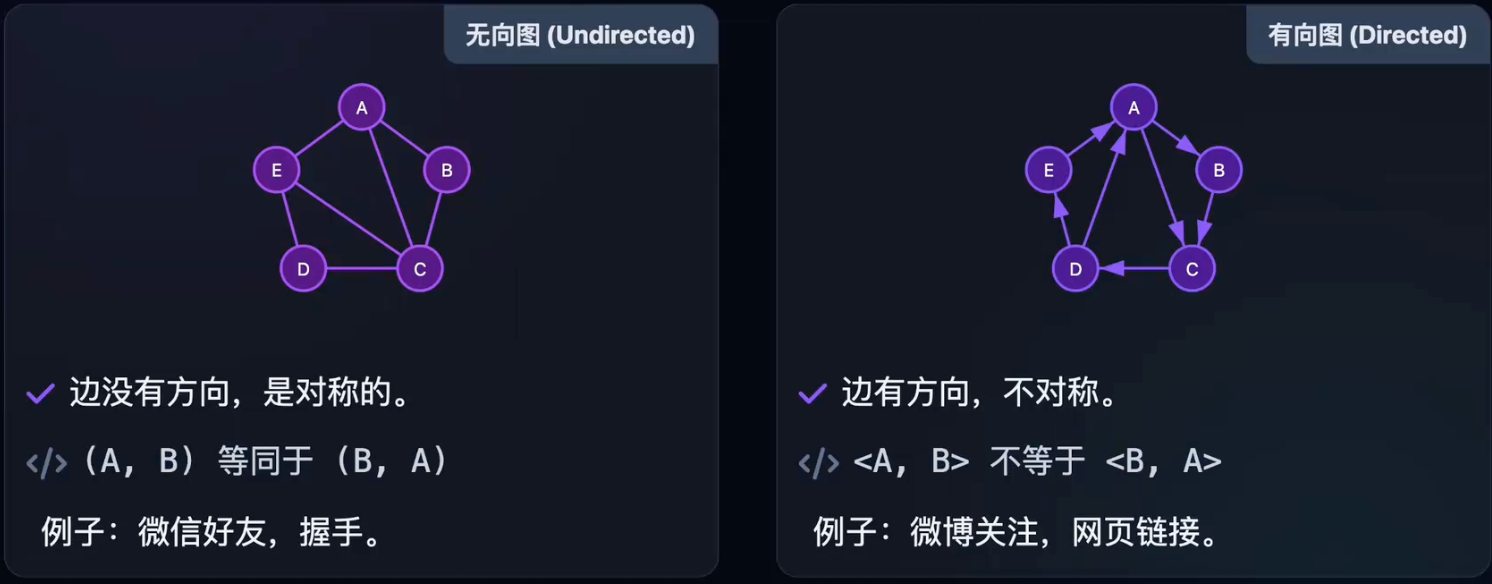
顶点的度
度(Degree)
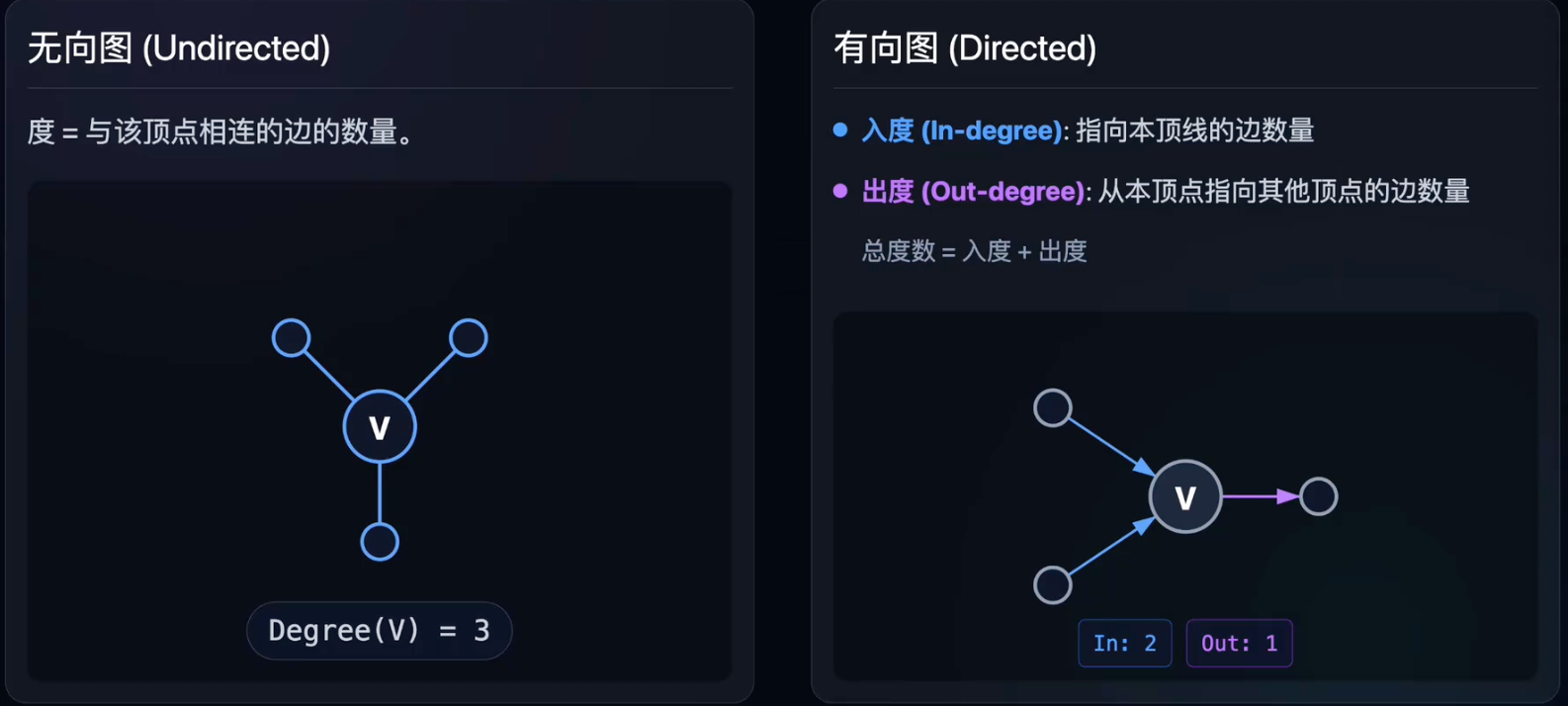
边的权重
定义:赋予边的数值,代表两个顶点之间关系的强度或成本。
常见含义:
- 地图:距离(km)、时间(min)。
- 网络:带宽(Mbps)、延迟(ms)。
- 社交:亲密度、互动频率。
带权图(Weighted Graph)又称为网(Network)。
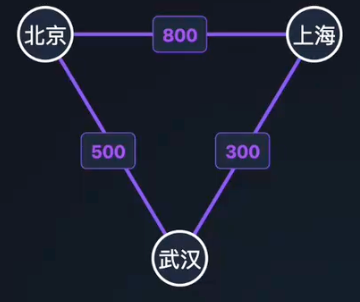
路径和环
路径(Path):从一个顶点到另一个顶点,途径的顶点序列。
简单路径:不重复经过顶点的路径。
环(Cycle):起点和终点相同的路径。
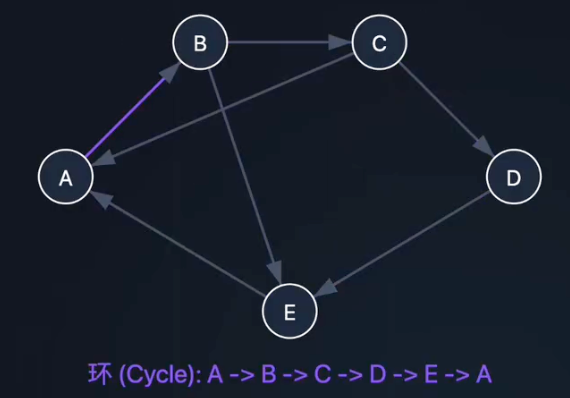
连通性
- 连通(Connected):顶点之间存在路径即为连通。
- 连通图(Undirected):任意亮点连通,若不连通则包含多个“连通分量”。
- 强连通(Directed):有向图中,任意两个顶点之间都可以互相到达。
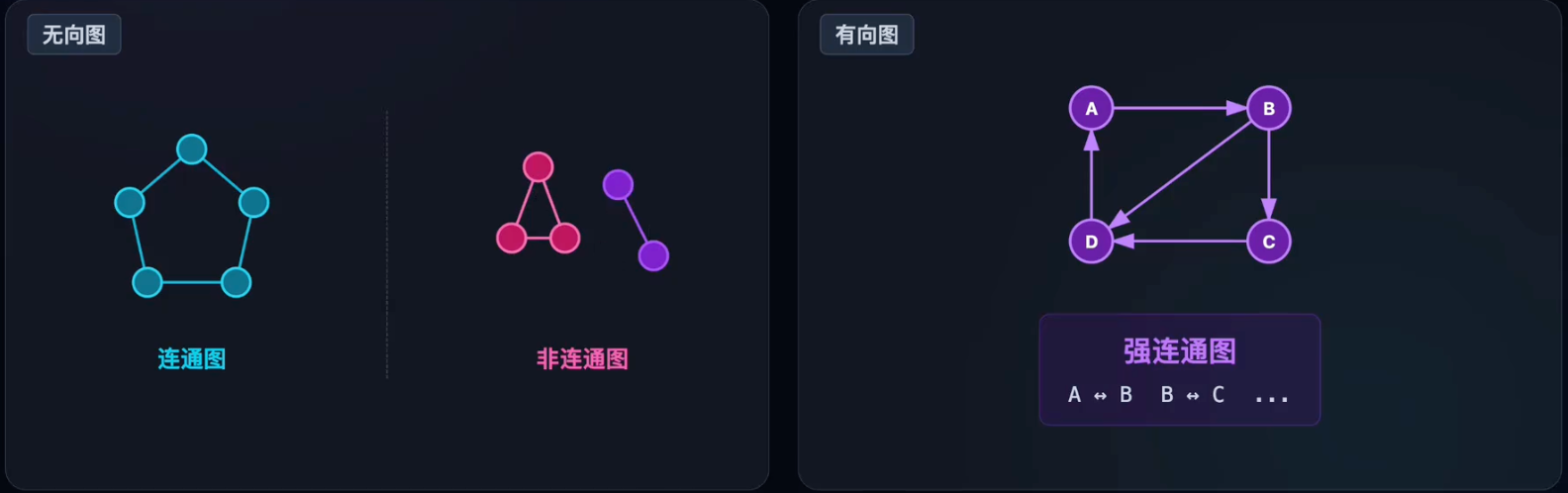
图的存储
邻接矩阵 & 邻接表
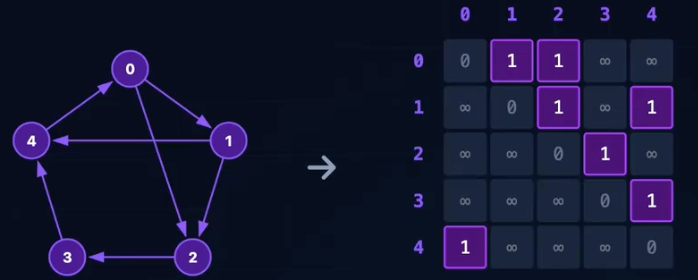
邻接矩阵
邻接矩阵:有向图(Directed)
定义:使用一个二位数组G[N][N]来表示顶点之间的连接关系。
- 若顶点i和j之间有边,则
G[i][j] = 1(或权重)。 - 若无边,则
G[i][j] = 0(或)。
特点:
- ✅查边快:O(1)判断两点是否相连。
- ✅算度快:行和 = 出度, 列和 = 入度。
- ⚠️耗空间:固定
,适合稠密图。
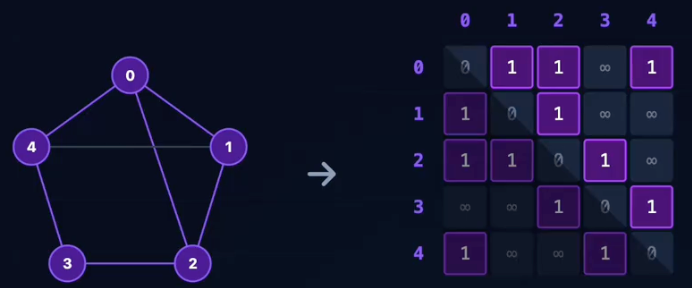
邻接矩阵:无向图(Undirected)
对称性(Symmety):无向图的边没有方向,(i, j)等同于(j, i)。
- 矩阵关于主对角线对称。
G[i][j] == G[j][i]- 存储时可以只存上三角或下三角以节省空间。
邻接矩阵:代码实现
#define MAX_V 100
#define INF 65535 // 表示无穷大(无边)
typedef struct{
char V[MAX_V]; // 顶点表
int Edge[MAX_V][MAX_V]; // 邻接矩阵(边表)
int numV, numE; // 当前顶点数和边数
}MGraph;
void CreateMGraph(MGraph *G){
// 1. 输入顶点数和边数
printf("输入顶点数和边数:");
scanf("%d %d", &G->numV, &G->numE);
// 2. 初始化邻接矩阵
for(int i = 0; i < G->numV; i ++){
for(int j = 0; j < G->numV; j ++){
if(i == j) G->Edge[i][j] = 0;
else G->Edge[i][j] = INF;
}
}
// 3. 建立边(读入边的数据)
int a, b, w
for(int k = 0; k < G->numE; k ++){
printf("输入边(vi,vj)的下标i, j和权重w:");
scanf("%d,%d,%d", &a, &b, &w);
G->Edge[a][b] = w;
G->Edge[b][a] = w; // 无向图需对称赋值
}
}邻接表
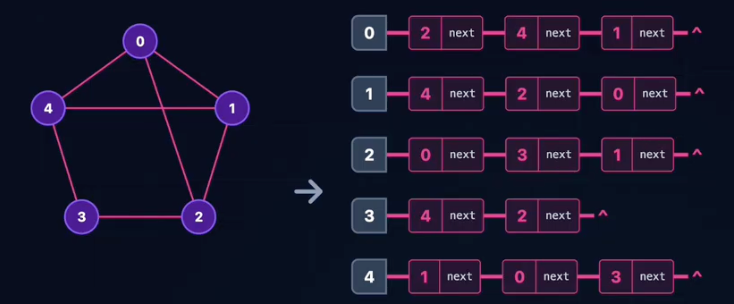
邻接表(Adjacency List)
定义:数组与链表的结合。每个顶点建立一个单链表,链表中存储该顶点的所有邻居。
- 顶点数组
AdjList[N]存储表头。 - 链表节点存储邻接点下标adjvex和权重weight。
特点:
- ✅节省空间,只存实际存在的边。
- ✅空间复杂度O(V + E)。
- ⚠️无向图中每条边存储两次(A -> B, B -> A)。
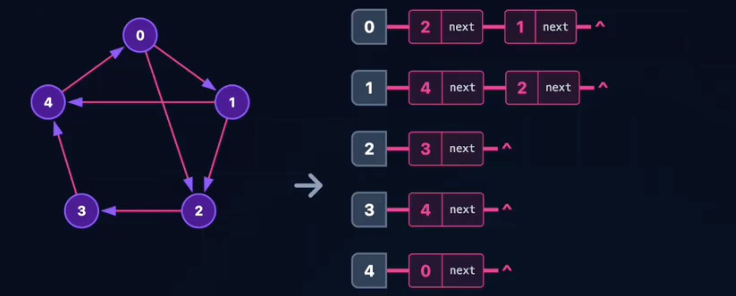
邻接表:无向图(Undirected)
冗余存储:无向图的边(i, j)没有方向,需要在两个顶点的链表中分别存储。
- 在
AdjList[i]中插入节点j。 - 在
AdjList[j]中插入节点i
影响:
- ⚠️边表节点总数是边数的2倍。
- ✅容易求顶点的度(链表长度即为度)。
邻接表:代码实现
关键点解析:
- 结构体嵌套:EdgeNode(边)挂在VertexNode(点)下。
- 头插法:新边插入链表头部,O(1)速度,但导致邻居顺序与输入相反。
- 出度容易,入度难:求入度需要遍历整个图(或者使用逆邻接表)。
typedef struct EdgeNode{
int adjvex; // 邻接点下标
int weight; // 权重
struct EdgeNode *next; // 指向下一个邻接点
}EdgeNode;
typedef struct VertexNode{
char data; // 顶点信息
EdgeNode *firstedge; // 边表头指针
}VertexNode, AdjList[MAX_V];
typedef struct{
AdjList adjList;
int numV, numE;
}GraphAdjList;
void CreateALGraph(GraphAdjList *G){
int i, j, k;
EdgeNode *e;
scanf("%d,%d", &G->numV, &G->numE);
// 初始化顶点表
for(i = 0; i < G->numV; i ++){
scanf("%c", &G->adjList[i].data);
G->adjList[i].firstedge = NULL;
}
// 头插法建立边表
for(k = 0; k < G->numE; k ++){
scanf("%d,%d", &i, &j);
e = (EdgeNode *)malloc(sizeof(EdgeNode));
e->adjvex = j;
e->next = G->adjList[i].firstedge;
G->adjList[i].firstedge = e;
// 无向图重复一次(j -> i)
e = (EdgeNode *)malloc(sizeof(EdgeNode));
e->adjvex = i;
e->next = G->adjList[j].firstedge;
G->adjList[j].firstedge = e;
}
}邻接矩阵vs邻接表
| 特性 | 邻接矩阵 (Matrix) | 邻接表 (List) |
|---|---|---|
| 空间复杂度 | ||
| 判断两点连接 | ||
| 找所有邻居 | ||
| 适用场景 | 稠密图,需要快速判断边的存在 | 稀疏图,频繁增删节点 |
| 实现难度 | 简单 (数组) | 中等 (指针操作) |
图的遍历
图的遍历:从图中某一顶点出发,按照某种搜索方法,对途中所有顶点访问一次且仅一次。
核心难点:
- 图可能有回路(环),如何避免兜圈子。
- 图可能不连通,如何访问孤立点。
- 解决方案:设置
visited[N]数组记录访问状态。
DFS深度优先搜索
- 像走迷宫:一条路走到黑,撞墙就回头。
BFS广度优先搜索
- 像水波扩散:由近及远,层层推进。
DFS
算法思想:
- 访问起始点v。
- 若v有未被访问的邻接点w,则从w出发继续深度遍历。
- 若所有邻接点都被访问过,则回退(Backtrack)到前一个顶点。
- 重复上述过程,直到所有通达节点都被访问。
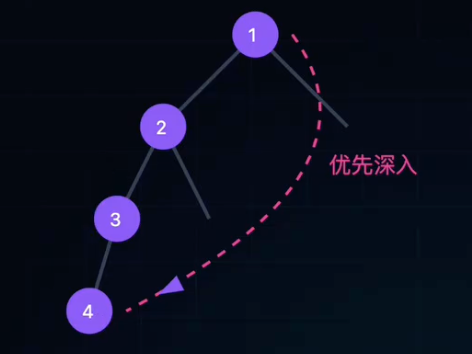
实现机制:
- 栈(Stack):后进先出(LIFO)。通常使用递归隐式使用系统栈。
代码解析:
- 递归基:隐式包含在循环条件中(无未访问邻居时函数结束,自动回溯)。
visited[]:至关重要,防止在环路中死循环。- 非连通图:DFSTraverse循环确保所有连通分量都被访问。
复杂度分析:
- 邻接矩阵:
————每次都要遍历一行找邻居。 - 邻接表:
————只遍历实际存在的边。
邻接矩阵DFS实现:
int visited[MAX_V]; // 访问标记数组
// 邻接矩阵的DFS递归算法
void DFS(MGraph G, int i){
int j;
// 1. 访问当前节点并标记
visited[i] = 1;
printf("%c ", G.vexs[i]);
// 2. 遍历所有邻接点
for(j = 0; j < G.numVertexes; j ++){
// 若有边且未被访问
if(G.arc[i][j] == 1 && !visited[i]){
DFS(G, j); // 递归调用
}
}
}
// 遍历整个图(处理非连通图)
void DFSTraverse(MGraph G){
int i;
for(i = 0; i < G.numVertexes; i ++)
visited[i] = 0; // 初始化
for(i = 0; i < G.numVertexes; i ++)
if(!visited[i])
DFS(G, i); // 对未访问的顶点调用DFS
}邻接表DFS实现:
BFS
算法思想:
- 访问起始点v。
- 依次访问v的所有未被访问的邻接点w1,w2...。
- 再依次访问w1,w2...的所有邻接点。
- 像波纹一样一层层向外扩展。
实现机制:
- 队列(Queue):先进先出(FIFO)。保证先被访问节点的邻居先得到访问。
关键逻辑:
- 入队时机:发现未访问邻居时立即入队并标记
visited[i]。 - 出队时机:处理完当前节点后出队,转而处理队列头部节点的邻居。
- 循环结构:外层循环处理非连通图,内层while循环处理当前连通分量。
void BFSTraverse(MGraph G){
int i, j;
Queue Q;
for(i = 0; i < G.numVertexes; i ++)
visited[i] = 0;
InitQueue(&Q); // 初始化辅助队列
for(i = 0; i < G.numVertexes; i ++){
if(!visited[i]){
visited[i] = 1;
printf("%c ", G.vexs[i]);
EnQueue(&Q, i); // 入队
while(!QueueEmpty(Q)){
DeQueue(&Q, &i); // 出队,顺便复制给i变量
// 找所有邻接点
for(j = 0; j < G.numVertexes; j ++){
if(G.arc[i][j] == 1 && !visited[j]){
visited[j] = 1;
printf("%c ", G.vexs[j]);
EnQueue(&Q, j); // 发现新节点,入队
}
}
}
}
}
}DFSvsBFS
| 维度 | 深度优先 (DFS) | 广度优先 (BFS) |
|---|---|---|
| 数据结构 | Stack (栈/递归) | Queue (队列) |
| 搜索路径 | 细长,迅速深入深层 | 宽广,层层推进 |
| 最优解 | 不能保证最短路径 | 能找到最短路径 (无权图) |
| 时间复杂度 | 两者相同。邻接矩阵 |
- DFS典型应用:全排列、寻找所有路径、拓扑排序、判断环、连通性检测。
- BFS典型应用:最短路径(迷宫/地图)、社交网络(几度好友)、Web爬虫、垃圾回收(GC)。
最小生成树
什么事最小生成树(MST)?
修路问题:假设有n个城市,需要在它们之间铺设光缆。已知任意两个城市间的铺设成本。
目标:如何选择线路,使得所有城市相互连通,且总成本最低?
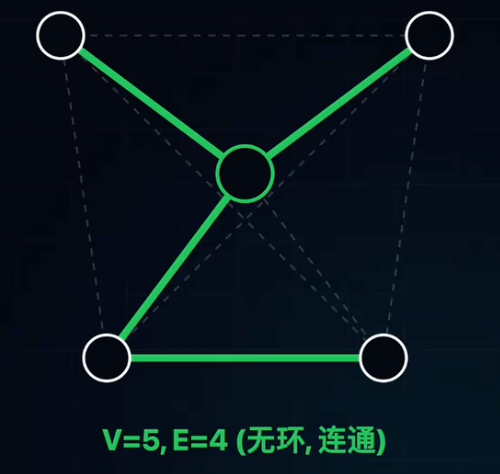
定义:MST
- 生成树:包含图中所有顶点,且没有环的子图(V个顶点,V-1条边)。
- 最小:边的权值之和最小。
Prim
核心思想:贪心(每次都找局部的最优解,最后得到全局的最优解)
- 从任意一个顶点出发,将其视为“已生成的树”。
- 每次从“树外”的节点中,挑选一个距离“树”最近的节点,加入到树中。
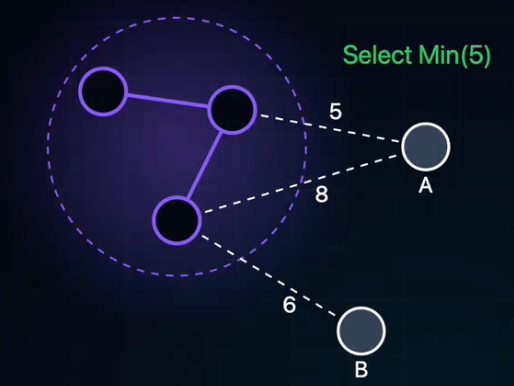
关键数据结构:
adjvex[i]:记录节点i依附在树上的哪个节点(即父节点)。lowcost[i]:记录节点i到当前生成树集合的最小距离。- 若
lowcost[i] == 0,表示节点i已在树中。
- 若
复杂度分析:
- 时间复杂度:
。 - 双重循环:外层循环V次,内层查找最小值+更新数组也是V次。
- 适用场景:稠密图(边数非常多时),因为其复杂度与边数无关。
关键逻辑:
- 核心在于
lowcost[j] = 0这一句,它标记了节点j已经“入伙”。 - 每次新节点入伙,都要用它去“更新”周围邻居到组织的距离。
void MiniSpanTree_Prim(MGraph G){
int min, i, j, k;
int adjvex[MAXV]; // 保存相关顶点下标(构建MST)
int lowcost[MAXV]; // 保存相关顶点间边的权值
// 1. 初始化:从顶点0开始构建
lowcost[0] = 0; // lowcost[i] = 0 表示i已经加入MST
adjvex[0] = 0;
for(i = 1; i < G.numV; i ++){
lowcost[i] = G.arc[0][i]; // 将与0相连的边权值存入
adjvex[i] = 0;
}
// 2. 循环 n-1 次,找剩余的 n-1 个顶点
for(i = 1; i < G.numV; i ++){
min = INF;
j = 1; // 当前树的顶点数
k = 0; // 当前最小边下标
// 寻找离当前MST最近的顶点k
while(j < G.numV){
if(lowcost[j] != 0 && lowcost[j] < min){
min = lowcost[j];
k = j; // k记录最小值的下标
}
j ++;
}
printf("(%d, %d) ", adjvex[k], k); // 打印当前最小边
lowcost[k] = 0; // 将k加入MST(标记为0)
// 3. 更新lowcost 数组(更新邻居距离)
for(j = 1; j < G.numV; j ++){
if(lowcost[j] != 0 && G.arc[k][j] < lowcost[j]){
lowcost[j] = G.arc[k][j]; // 发现通过k到j的距离更近
adjvex[j] = k; // 更新j的父节点为k
}
}
}
}Kruskal
Kruskal算法:加边法
核心思想:
- 不属于任何一个点,而是着眼于边。
- 将所有边按权值从小到大排序,依次尝试加入。
- 如果加入某条边会形成环,则丢弃;否则保留。
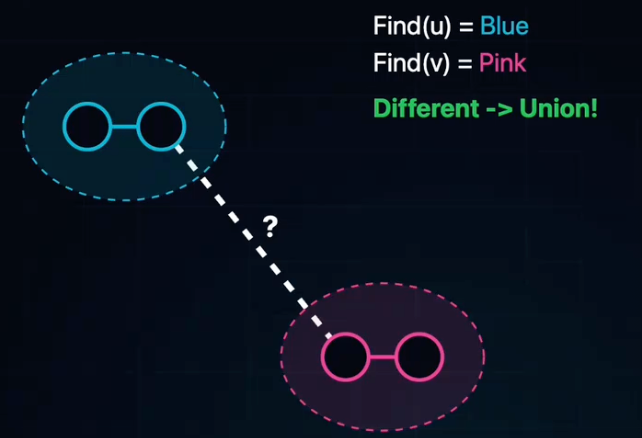
关键技术:并查集
- 判环:如何快速判断两个点是否已经连通?
Find(x):查找x所属集合的根节点。Union(x, y):合并两个集合。- 若
Find(u) == Find(v),说明u,v已连通,加边必成环 --> 跳过。
复杂度分析:
- 时间复杂度:O(E log E)。
- 主要耗时在排序上。并查集的操作接近O(1)。
- 适用场景:稀疏图(边数较少时),因为只与边数E有关。
实现细节:
parent[]数组初始化为0。- Find函数通过不断向上找父节点直到为0来找到根。
- 路径压缩(Path Compression)可进一步优化查找效率。
typedef struct{
int begin, end, weight;
}Edge;
// 查找集合根节点
int Find(int *parent, int f){
while(parent[f] > 0) f = parent[f];
return f;
}
void MiniSpanTree_Kruskal(MGraph G){
int i, n, m;
Edge edges[MAXE]; // 边集数组
int parent[MAXV]; // 并查集数组(判断环)
sort(edges); // 1. 核心:将边按权值从小到大排序
for(i = 0; i < G.numV; i ++) parent[i] = 0; // 初始化并查集
for(i = 0; i < G.numE; i ++){
n = Find(parent, edges[i].begin); // 查找起点所属集合
m = Find(parent, edges[i].end); // 查找终点所属集合
// 2. 若不属于同一集合(说明无环)
if(n != m){
parent[n] = m; // 合并两个集合
printf("(%d, %d) ", edges[i].begin, edges[i].end);
}
}
}路径压缩实现:
// 初始化方式改为:
for(int i = 0; i < G.numV; i ++) parent[i] = i;
// find()函数为:
int find(int *parent, int f){
if(parent[f] != f) parent[f] = find(parent[f]); // 在find()的过程,父节点会改成根节点,压缩寻找根节点的路径。
return parent[f];
}PrimvsKruskal
| 维度 | Prim 算法 | Kruskal 算法 |
|---|---|---|
| 核心策略 | 加点法 (Growing Tree) | 加边法 (Forest Merger) |
| 时间复杂度 | ||
| 适用场景 | 稠密图 (边多) | 稀疏图 (边少) |
| 数据结构 | lowcost 数组 | 并查集 (Union-Find) |
- 两者都是贪心算法(Greedy)的经典应用,都基于切分定理。
最短路径
定义:
- 在带权图中,寻找从起点(Source)到终点(Destination)的路径,使得路径上所有边的权值之和最小。
Dijkstra
Dijkstra适用场景:
- 单源最短路径(One-to-All):求图中某一顶点到其他所有顶点的最短路径。
- 限制条件:不适用于包含负权边的图。
核心思想(由近及远,层层刷新):
- 选最近:每次都在还没确定的点里,挑一个离起点最近的,直接把它的最短路“锁死”。
- 做跳板:利用这个刚“锁死”的点作为中转站,去问问它的邻居们“从我这走,会不会比你们原来的路更近?”
- Dijkstra算法就是从起点开始,像水波纹一样向外扩散,每次锁定一个离波纹中心最近的点,利用这个点作为新的波源,去触达更远的地方,知道覆盖全图。
关键数组:
dist[i]:起点到顶点i的当前最短距离。pre[i]:记录顶点i在最短路径上的前驱节点(用于还原路径)。visited[i]:标记顶点i的最短路径是否已确定。
复杂度分析:
- 时间复杂度:
。 - 若使用优先队列(堆优化),可降至
。
注意事项:
- ⚠️Dijkstra算法不适用于包含负权边的图。如果有负权边,需要使用Bellman-Ford算法。
void dijkstra(MGraph G, int v0, int pre[], int dist[]){
// 循环变量及最小值临时变量
int i, j, u, min;
// 标记数组,visited[i]=1表示已确定
int visited[MAXV];
// 1. 初始化所有节点状态
for(i = 0; i < G.numVertexes; i ++){
// 初始化所有节点均未被访问
visited[i] = 0;
// 将所有节点的距离初始化为无穷大
dist[i] = INF;
// 初始化前驱节点为-1(无前驱)
pre[i] = -1;
}
// 起点到自身的距离为0
dist[v0] = 0;
// 2. 主循环:每次确定一个节点的最短路径
for(i = 0; i < G.numVertexes; i ++){
// 初始化当前最小距离为无穷大
min = INF;
// 初始化最近节点索引为无效值
u = -1;
// 2. 贪心选择:在未标记节点中寻找距离最近的节点u
for(j = 0; j < G.numVertexes; j ++){
// 如果节点j未被标记且距离小于当前最小值
if(!visited[j] && dist[j] < min){
// 更新最小值
min = dist[j];
// 记录该节点索引
u = j;
}
}
// 如果找不到可达节点,跳出循环
if(u == -1) break;
// 将找到的最近节点u标记已确定
visited[u] = 1;
// 2.2 松弛操作:更新节点u的所有邻居j
for(j = 0; j < G.numVertexes; j ++){
// 如果节点j未被标记且u到j之间有边相连
if(!visited[j] && G.arc[u][j] < INF)
// 核心判断:经过u到达j的距离是否比原来更短?
if(dist[u] + G.arc[u][j] < dist[j]){
// 更新j的最短距离
dist[j] = dist[u] + G.arc[u][j];
// 更新j的前驱节点为u
pre[j] = u;
}
}
}
}什么是“贪心”?
- 总是做出在当前看来最好的选择。
- 不考虑长远的整体规划,而是通过每一步的局部最优,试图达成全局最优。
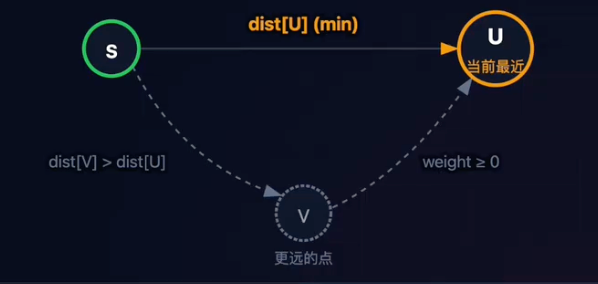
Dijkstra的“贪心时刻”:
- 选最近:在所有未确定的节点中,选离起点最近的那个。
- 不回头:一旦选定,就认为“这就是最短路了”,标记为已确定,不再更改。
为什么“只看眼前”是正确的?
- 既然U是当前最近的(
dist[U] < dist[V]),那么dist[V] + weight必然大于dist[U]。
Floyd
定义:
- 寻找图中任意两个顶点之间的最短路径。
- 不同于Dijkstra(单源),Floyd算法一次性求出所有点堆的最路距离。
Floyd适用场景:
- 多源最短路径(All—Pairs):需要知道任意两点间距离,不仅是起点到其他点。
适用范围:
- ✅允许负权边。
- ❎不允许负权回路。
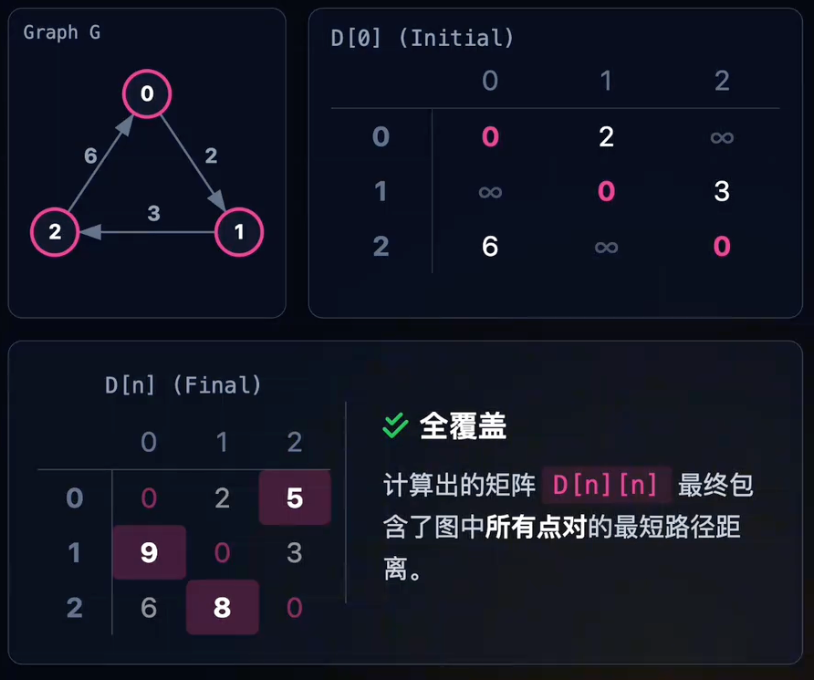
动态规划思想:
- 每次引入一个新的中间点k,检查是否能通过k缩短任意两点
(i, j)间的路径。 - 最优子结构:
- 原问题的最优解,包含着子问题的最优解。
- 如果最短路径经过k,那么分段路径i->k和k->j也一定是最优的。
- 算法本质:
- 试图通过动态规划,并行地解决V次Dijkstra问题。
- 底层都依赖于相同的“松弛”(Relaxation)原理。
- 状态转移方程:
D[i][j] = min(D[i][j], D[i][k] + D[k][j])
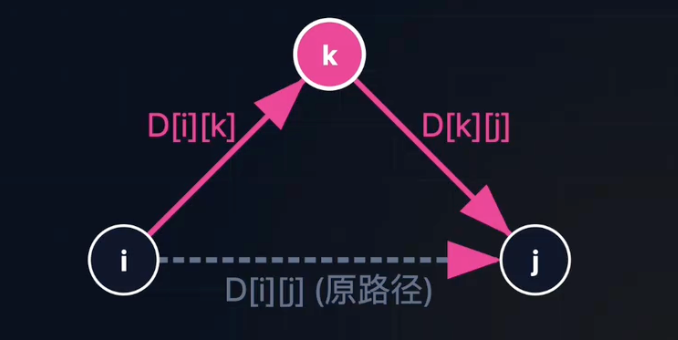
void Floyd(MGraph G){
int i, j, k;
int D[MAXV][MAXV];
int P[MAXV][MAXV]; // 路径矩阵
// 1. 初始化
for(i = 0; i < G.numVertexes; ++ i){
for(j = 0; j < G.numVertexes; ++ j){
D[i][j] = G.arc[i][j];
P[i][j] = j; // 初始化路径
}
}
// 2. 三重循环核心算法
// k:中转节点(必须在最外层)
for(k = 0; k < G.numVertexes; ++ k){
// i:起点
for(i = 0; i < G.numVertexes; ++ i){
// j:终点
for(j = 0; j < G.numVertexes; ++ j){
// 如果经过k能缩短到i到j的距离
if(D[i][k] + D[k][j] < D[i][j]){
// 更新距离
D[i][j] = D[i][k] + D[k][j];
// 更新路径前驱
P[i][j] = P[i][k];
}
}
}
}
}复杂度分析:
- 时间复杂度:
。 - 空间复杂度:
(存储二维矩阵)。 - 虽然复杂度高,但常数小,且代码极其简单,适合节点数较少(
)的图。
易错点:
- k(中转点)必须在最外层。
- 因为算法本质是“逐步引入中间点k”,所以k必须作为阶段划分的最外层循环。
DijkstravsFloyd
贪心vs动态规划:
- Dijkstra(贪心):
- 每次“贪婪”地选择当前距离最近的未知节点。
- 像走迷宫,每次只走确定的最短一步,不回头。
- Floyd(动态规划):
- 逐步扩大“允许经过的中转点集合”。
- 像拼图,先拼好局部(只经过0),再拼更大局部(经过0,1)...
核心区别:
- Dijkstra关注“点”的扩展(从源点向外辐射)。
- Floyd关注“路径”的优化(通过中转点松弛)。
| 维度 | Dijkstra | Floyd |
|---|---|---|
| 解决问题 | 单源最短路径 | 多源最短路径 |
| 时间复杂度 | ||
| 空间复杂度 | ||
| 负权边 | ❌ 不支持 | ✅ 支持 |
| 实现难度 | 中等 (需辅助结构) | 极简 (三重循环) |
关键路径
拓扑排序
定义:
- 拓扑排序(Topological Sort)是针对有向无环图(DAG)的一种节点线性排序方法。
- 核心约束:对于每一条有向边u->v,在排序结构中,u一定出现在v之前。
- 本质:解决“先做什么、后做什么”的依赖顺序问题。
基本思想:
- “每次找到一个没有前驱(入度为0)的顶点,将其输出,并删去该顶点及其发出的所有边。”
详细步骤:
- 统计入度:遍历图,计算每个顶点的入度(Indegree)。
- 入栈:将所有入度为0的顶点压入栈(Stack)。
- 循环处理:
- 弹出栈顶的顶点V,输出V。
- 遍历V的所有邻接点W,将W的入度减1.
- 如果W的入度变为0,则将W入栈。
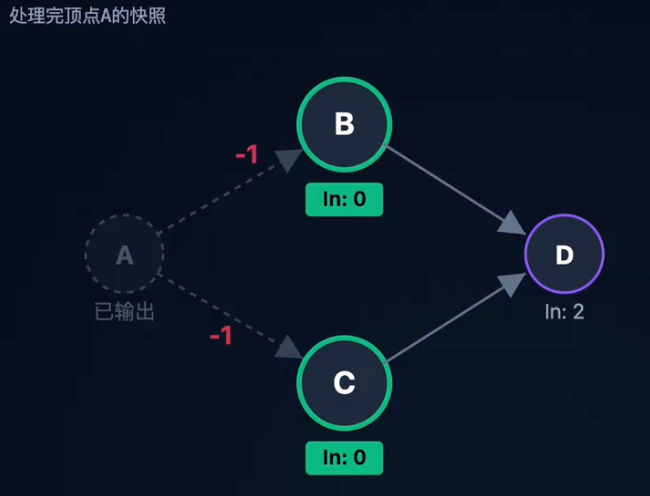
关键点解析:
- 邻接表结构:方便查找每个顶点的邻接点(出边)。
- 入度数组:需预先计算好,存储在
adjList[i].in中。 - 辅助数据结构:使用栈(Stack)来存储当前入度为0的顶点。
复杂度分析:
- 时间复杂度:O(V + E),初始化扫描为入度表O(V),每个顶点入栈出栈一次O(V),每条边被访问一次O(E)。
- 空间复杂度:O(V),需要维护入度数组和栈。
// 边表结点
typedef struct EdgeNode{
int adjvex; // 顶点对应的下标
struct EdgeNode *next; // 指向下一个临界点
}EdgeNode;
// 顶点表结点
typedef struct VertexNode{
int in; // 顶点入度
int data; // 顶点数据
EdgeNode *firstedge; // 边表头指针
}VertexNode, AdjList[MAXVEX];
// 图结构
typedef struct{
AdjList adjList;
int numV, numE;
}GraphAdjList;
Status TopologicalSort(GraphAdjList GL){
EdgeNode *e;
int i, k, current;
int top = 0;
int count = 0;
int *stack = (int *)malloc(Gl.numV * sizeof(int));
// 1. 初始化:遍历所有顶点,将入度为0的顶点入栈
for(i = 0; i < GL.numV; i ++)
if(GL.adjList[i].in == 0)
// 入栈操作
stack[++ top] = i;
// 2. 主循环:只要栈不为空,就继续处理
while(top != 0){
// 出栈,获取当前处理的顶点下标
current = stack[top --];
printf("%d -> ", GL.adjList[current].data);
count ++;
// 遍历当前顶点的所有邻接点(出边)
// 获取第一条边
e = GL.adjList[current].firstedge;
while(e){
// k是current的邻接点下标
k = e->adjvex;
// 入度减1
if(!(-- GL.adjList[k].in))
// 入度为0的顶点入栈
stack[++ top] = k;
// 指向下一条边
e = e->next;
}
}
// 3. 环检测:如果输出的顶点数少于总顶点数,说明图中有环
if(count < GL.numV)
return ERROR;
else
return OK;
}AOE网
核心定义:
- 在一个表示工程的有向无环图(DAG)中:
- 顶点(vertex):表示事件(Event)。如“食材备好”、“可以开饭”。
- 有向边(Edge):表示活动(Activity)。如“打鸡蛋”、“炒菜”。
- 权值(Weight):表示活动持续的时间。
性质:只有在某顶点代表的事件发生后,从该顶点出发的活动才能开始。
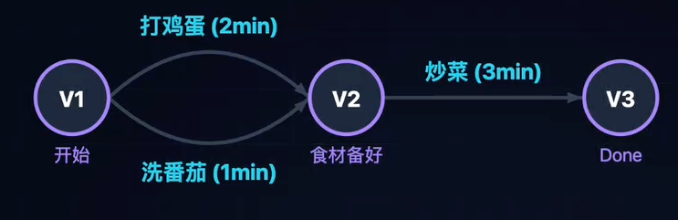
工程的总工期取决于最长的那条路径长度,这条路径被称为关键路径(Critical Path)。
关键参数解析:
- 事件(顶点)参数:
ve(i):最早发生时间(Earliest),事件i最早可以在什么时候发生?取决于所有前驱活动都完成的时间点。vl(i):最晚发生时间(Latest),事件i最晚必须在什么时候发生?为了不拖延整个工期,最迟不能晚于这个时间点。
- 活动(边)参数:
e(k):最早开始事件(Earliest),活动k最早什么时候能开工?等于其起点事件的最早发生时间ve(i)。l(k):最晚开始事件(Latest),活动k最晚必须什么时候开工?等于终点最晚事件减去耗时:vl(j) - weight。
拓扑排序 & AOE网